

文章目录
论文摘要
论文为A Survey on Knowledge Graphs: Representation, Acquisition and Applications,发表日期2020年,论文PDF,点击链接。
代表实体间结构关系的知识图谱已成为认知和人类智能研究的一个日益流行的方向。在这篇论文中,作者对知识图谱进行了全面的回顾,涵盖了1)知识图谱表示学习、2)知识获取和补全、3)时序知识图谱、4)知识感知应用等方面的研究主题,并总结了最近的突破和未来的研究方向。作者对这些主题进行全视图分类。知识图谱嵌入从表示空间、得分函数、编码模型和辅助信息四个方面进行组织。对知识获取,特别是知识图的完成、嵌入方法、路径推理和逻辑规则推理进行了综述。同时进一步探讨了一些新兴的主题,包括元关系学习、常识推理和时序知识图谱。为了方便未来对知识图谱的研究,论文还提供了一个针对不同任务的数据集和开源库的管理集合。最后,对几个有前景的研究方向进行了深入的展望。
如果只是看着玩玩可以穿梭到这篇博文:
知识图谱
知识图谱的术语与知识库是同义的,只是稍有不同。当考虑知识图谱的图结构时,可以看作是一个图。当它涉及到形式语义时,它可以作为解释和推断事实的知识库。知识可以在资源描述框架(RDF)下以事实三元组的形式表示(头、关系、尾)或(主语、谓语、宾语),例如(Albert Einstein, WinnerOf, Nobel Prize)。它也可以表示为一个有向图,其中节点是实体,边是关系。下图是知识库和关系图示例。

历史
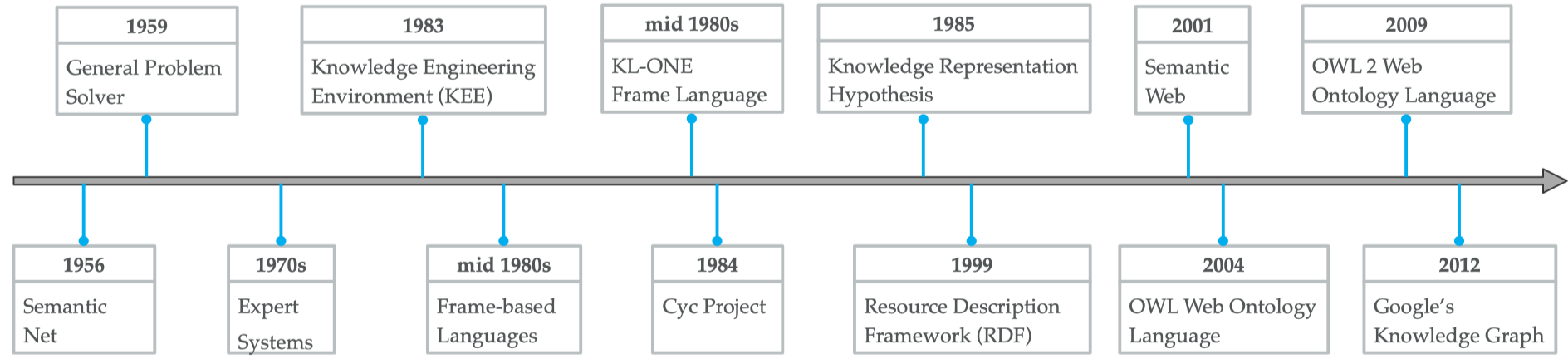
知识表示在逻辑和人工智能领域经历了漫长的发展历史。图形化知识表示的概念最早可以追溯到1956年Richens提出的语义网概念,而符号逻辑知识可以追溯到1959年的一般问题求解者。知识库首先用于基于知识的推理和问题解决系统。MYCIN是最著名的基于规则的医学诊断专家系统之一,其知识库约有600条规则。后来,人类知识表示的社区看到了基于框架的语言、基于规则的和混合表示的发展。大约在这一时期的末期,Cyc项目1开始了,旨在汇集人类知识。资源描述框架(RDF) 2和Web本体语言(OWL) 3相继发布,成为语义Web 4的重要标准。然后,许多开放知识库或本体被发布,如WordNet、DBpedia、YAGO和Freebase。Stokman和Vries在1988年的一篇图论中提出了结构知识的现代概念。然而,知识图谱的概念自2012年谷歌的搜索引擎5首次推出以来,得到了极大的普及,提出了知识库的知识融合框架来构建大规模的知识图谱。
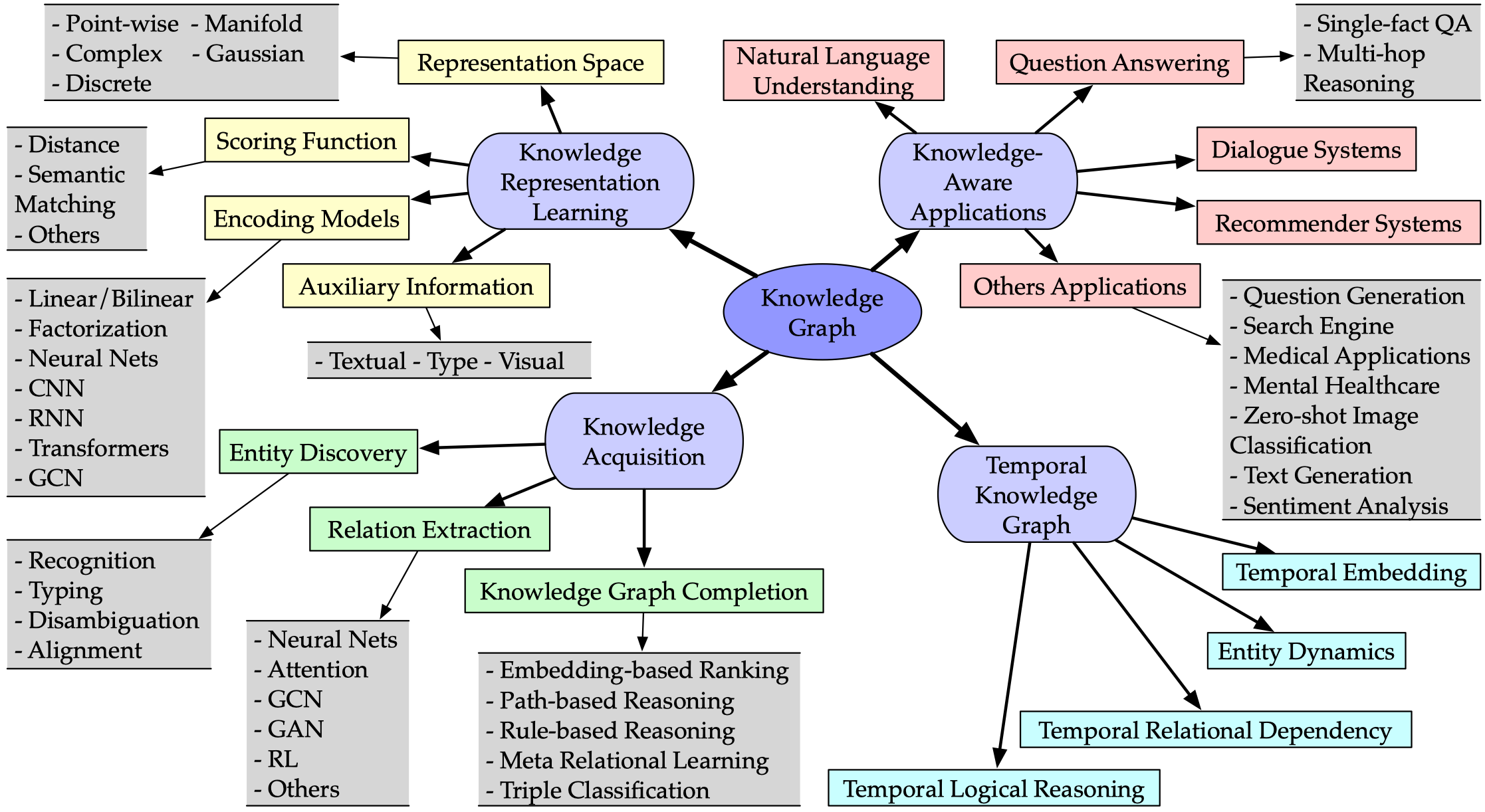
知识图谱研究方向
包含四个主要方面
1)知识图谱表示学习、2)知识获取和补全、3)时序知识图谱、4)知识感知应用
知识表示学习(Knowledge Representation Learning)
知识表示学习是知识图谱的一个重要研究课题,它为许多知识获取任务和后续应用铺平了道路。作者将KRL分为表示空间、评分函数、编码模型和辅助信息四个方面,为开发KRL模型提供了清晰的工作流程。具体的材料包括:
- 1)关系和实体所表示的表示空间;
- 2)测量事实三元组可信性的打分函数;
- 3)编码用于表示和学习关系交互的模型;
- 4)将辅助信息纳入到嵌入方法中。
表示学习包括点向空间、流形空间、复向量空间、高斯分布和离散空间。评分指标一般分为基于距离的评分函数和基于相似度匹配的评分函数。目前的研究主要集中在编码模型,包括线性/双线性模型,因子分解和神经网络。辅助信息包括文本信息、可视信息和类型信息。
表示学习实际上也就是嵌入,可以参考知识图谱嵌入综述论文(Knowledge Graph Embedding: A Survey of Approaches and Applications),这篇讲得更清晰,论文讲解可以参考以下两篇。
知识获取(Knowledge Acquisition)
知识获取任务分为三类:
- 知识图谱补全(KGC)
- 关系提取(RE)
- 命名实体识别(NER)
第一个用于扩展现有的知识图,而其他两个用于从文本中发现新知识(即关系和实体)。KGC可分为以下几类:基于嵌入的排序、关系路径推理、基于规则的推理和元关系学习。实体发现包括识别、消歧、类型化和对齐。关系提取模型利用了注意机制、图卷积网络(GCNs)、对抗性训练、强化学习、深度剩余学习和转移学习。
时序知识图谱(Temporal Knowledge Graphs)
时序知识图谱结合时间信息进行表示学习,也就是在三元组上添加一个时间标签。此研究主要分为时间嵌入、实体动态、时间关系依赖、时间逻辑推理四个研究领域。
知识图谱应用(Knowledge-aware Applications)
知识感知应用程序包括自然语言理解(NLU)、问答系统、推荐系统和各种真实世界的任务,这些应用程序注入知识以改进表示学习。
发展前景和方向
更加复杂的推理
知识表示和推理的数值计算需要一个连续的向量空间来捕捉实体和关系的语义。基于嵌入的方法对于复杂的逻辑推理有一定的局限性,关系路径和符号逻辑的两个方向都值得进一步探索。一些有前途的方法如循环关系路径编码、基于GNN的消息传递知识图谱、基于强化学习的路径查找和推理等,在处理复杂推理时都是很有前途的。对于逻辑规则和嵌入的组合,一些工作结合了马尔科夫逻辑网络与KGE,旨在利用逻辑规则和处理他们的不确定性。利用有效的嵌入实现对不确定性和领域知识的概率推理将是一个值得关注的研究方向。
统一框架展开研究
将知识图谱和文本放在同一个屋檐下,可以有一种相互关注的知识图和文本信息共享的联合学习框架,以类似于图网络统一框架的方式进行统一化的研究。
可解释性
最近的神经模型在透明性和可解释性方面存在局限性,尽管它们已经取得了令人印象深刻的性能。一些方法结合了黑盒神经模型和符号推理,通过结合逻辑规则来提高互操作性。可解释性可以说服人们相信预测。因此,进一步的工作应该是提高预测知识的可解释性和可靠性。
可扩展性
对大规模的知识图谱十分必要。
知识的信息聚合
全局知识的聚合是知识感知应用的核心。例如,推荐系统使用知识图谱对用户-项目交互和文本分类进行建模,将文本和知识图谱编码到语义空间中。现有的知识聚合方法大多设计了注意机制和GNNs等神经结构。自然语言处理社区通过Transformer和BERT模型等变体的大规模预训练得到了发展,而最近的一项发现表明,对非结构化文本进行预训练的语言模型实际上可以获得某些事实知识。大规模的预培训可以是一种直接的知识注入方式。然而,以一种有效的、可解释的方式重新思考知识聚合的方式也具有重要意义。
图谱的自动构建
当前的知识图谱高度依赖于手工构建,这是劳动密集型且昂贵的。知识图谱在不同认知智能领域的广泛应用,要求从大规模的非结构化内容中自动构建知识图谱。面对多模态、异构和大规模的应用,自动构建仍然是一个巨大的挑战。
最后补充一个论文中没有的方向ELG:事理知识图谱。



