

黑暗森林
宇宙就是一座黑暗森林,每个文明都是带枪的猎人,像幽灵般潜行于林间,轻轻拨开挡路的树枝,竭力不让脚步发出一点儿声音,连呼吸都必须小心翼翼:他必须小心,因为林中到处都有与他一样潜行的猎人,如果他发现了别的生命,能做的只有一件事:开枪消灭之。在这片森林中,他人就是地狱,就是永恒的威胁,任何暴露自己存在的生命都将很快被消灭,这就是宇宙文明的图景。——《三体:黑暗森林》

我在末日等你
抛去黑暗森林的道德,结构上,知识何尝不是无穷尽的森林。识盈虚之有数,觉宇宙之无穷。千年以前的哲人认识到在宇宙维度中人类的渺小。同样,知识深邃,即使穷尽一生,也没有人能做到完全透彻。
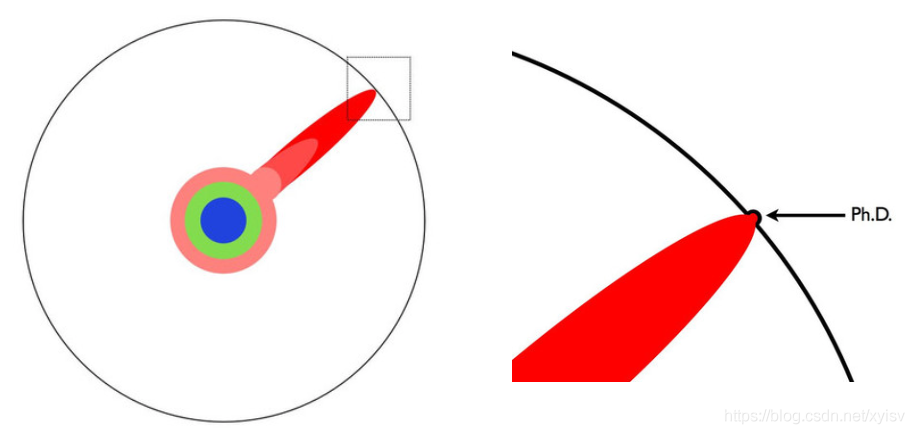
知识如圆(黑色框为人类的知识,彩色圆为一个Ph.D.的知识,矩形框为一个Ph.D.对知识的贡献)
好在知识图谱(Knowledge Graph)给出了一种取巧的方式,让人类能在知识的森林中有效地获取高价值的信息。本期笔者将带领大家乘坐水滴,一睹知识图谱的前世今生。
大爆炸
当第一台人造计算机ENIAC问世时,数据这个概念便脱颖而出,其规模按照每年50%的速度增长(存疑)。纵观宇宙历史,从人类能够记载的数据起算至今,不过转瞬之间。到了二十一世纪,大数据普及对数据的组织、挖掘及应用提出了更高的要求。同爱因斯坦梦寐以求的大统一理论类似,数据科学界通过知识图谱的构建,对数据产生的各种问题统一建模。
知识图谱本质上是一种图结构,由节点和边组成。节点代表一个实体(entity),边代表某种关系(relation),因此我们也可以把知识图谱看成三元组的集合。知识图谱不是一个新的概念,最早可追溯到上个世纪的语义网络(Semantic Network)[1],其最初的目的是将万维网中的文本链接转化为语义网络以表示实体的链接。2012年,Google将知识图谱加入搜索引擎,使用语义检索从多种来源收集信息,以提高Google搜索的质量。
谷歌搜索引擎
知识图谱的构建是一个系统工程,从原始的数据到形成知识图谱,经历了知识抽取、知识融合(实体对齐)、数据模型构建、质量评估等步骤。
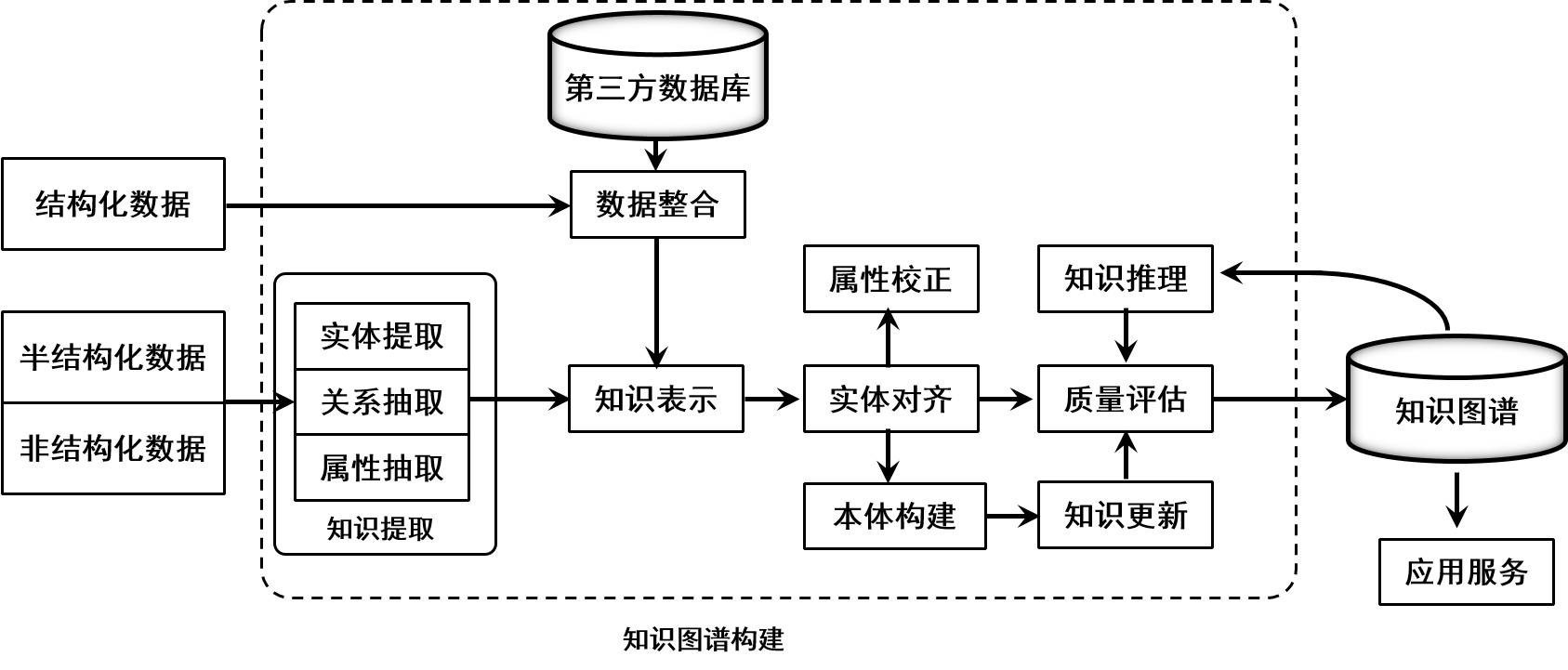
知识图谱构架流程
曲率飞船
宇宙中的行星,恒星和星系数不胜数,人类可以用眼睛感受到它们的存在,但是由于光速和时间的制约,无法实现星际飞行,与它们真正建立起联系。另一方面,人类目前的技术被智子封锁(存疑),进一步降低了曲率飞船研究成功的可能性。
在数据的范畴中,知识图谱实体关系提取技术则扮演曲率飞船这一关键角色,在大量的非结构化的数据中建立联系。例如有一文本:“香港在1997年7月1日回归中国。”,通过实体关系提取,可以获得两个实体:香港、中国,一个关系:属于,这就构成了一个知识图谱三元组<香港,属于,中国>。
实体关系抽取是一个经典任务,特征工程、核方法、图模型曾被广泛应用其中,取得了一些阶段性的成果。随着深度学习时代来临,神经网络模型则为实体关系抽取带来了新的突破[2]。在经过知识抽取这一步骤后,我们获得了相应的三元组,名义上已经完成了知识图谱构建工作。
平行宇宙
在很多情况下,某一方面的知识图谱是独立存在的。不同的领域、不同的语言在不同的时间会产生不同的知识图谱。例如维基百科,百度百科可以构造两种知识图谱,除此以外还有学者知识图谱,电影知识图谱等。每一个图谱都是一个独立的宇宙,知识融合技术(Knowledge Fusion)能够让知识在平行宇宙中进行自由穿梭[4]。
知识融合的目的是为了合并不同的数据源的信息,包括数据模式层和数据层的匹配融合。它主要分为以下三个部分
- 本体匹配(Ontology Matching)
- 实体对齐(Entity Alignment)
- 冲突检测与消歧(Disambiguation)
本体匹配侧重发现模式层等价或相似的类、属性或关系,也成为本体映射、本体对齐;实体对齐侧重发现指称真实世界相同对象的不同实例,也称为实体解析、实例匹配。
在本体匹配和实体对齐领域,传统的方法通过设计相应的相似度计算算法,融合不同的对象。目前,由于网络表示学习的兴起,基于嵌入表示(参考下一节)的实体对齐成为目前研究的热点。知识图谱融合技术提升了数据的质量,为构建大规模知识网络提供了可行性。
降维打击
二向箔是歌者文明采用的宇宙规律武器之一,它能够使空间中的一个维度无限蜷缩,从而迫使三维宇宙及其中的所有物质向二维宇宙坍塌,专门用于清除那些具备星际航行能力但尚未拥有曲率技术的弱小文明。

歌者
和二向箔的原理类似,知识图谱嵌入(Knowledge Graph Embeddding)也是一种降维技术,目的是将实体和关系映射到低维稠密的向量空间。
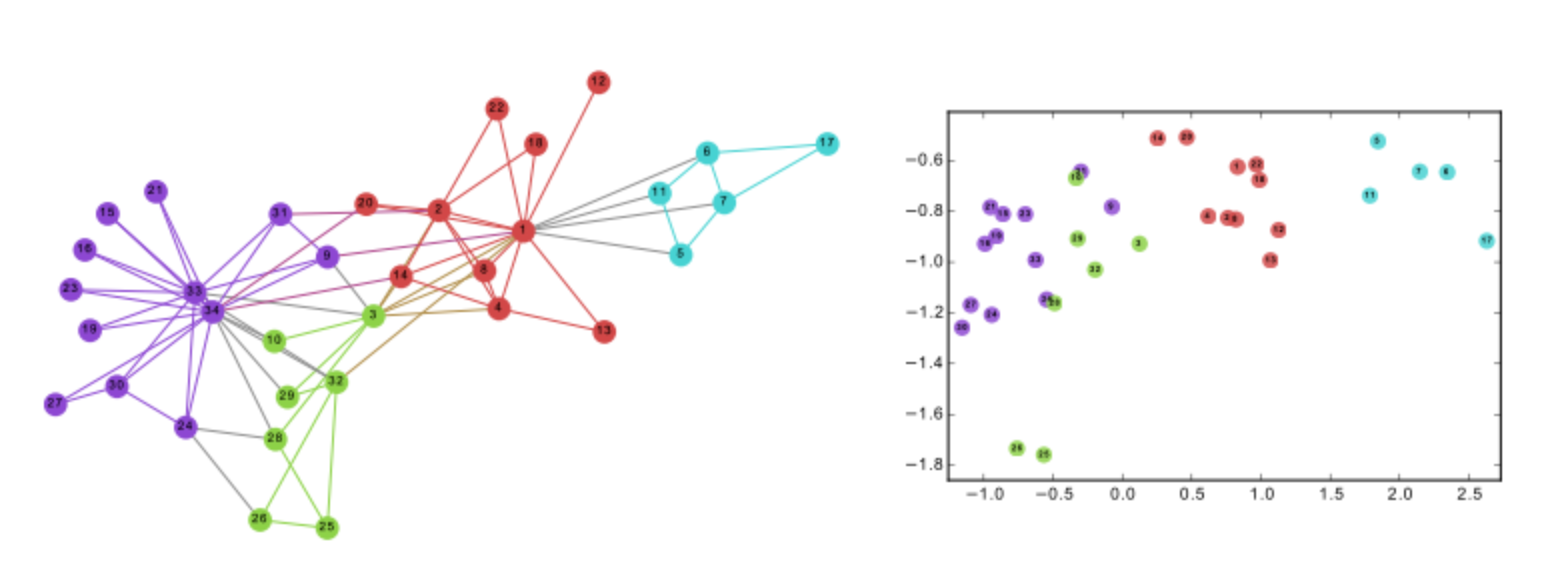
知识图谱嵌入(这里为网络嵌入算法DeepWalk的示意)
它是网络嵌入的子集,也是表示学习的一个分支。目前,知识图谱嵌入包含两大类:融合事实信息和融合附加信息的知识嵌入[3]。其中前者又包含两个子类,一种基于翻译(平移)距离模型,另一种基于语义匹配模型。
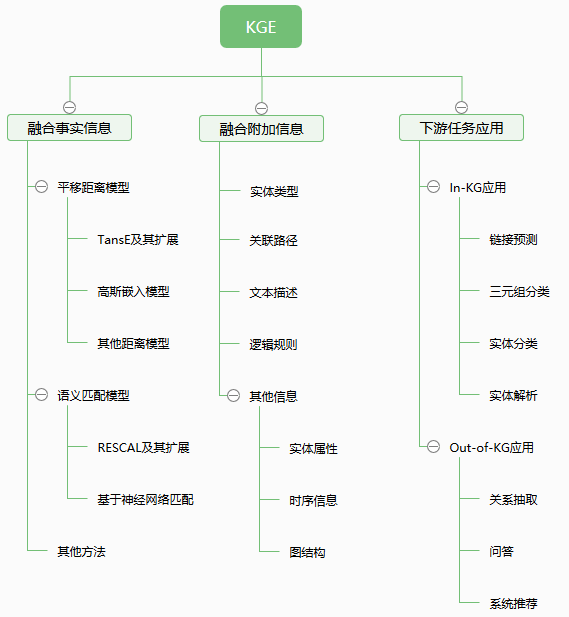
知识图谱嵌入技术概览
在获得了三元组的嵌入表示后,我们可以通过这些嵌入向量设计种类丰富的下游任务。例如实体对齐、链接预测(包括知识图谱补全技术)、实体分类、问答系统和推荐系统等,这在一定程度上提高了知识图谱的应用范围,成为知识图谱技术落地的关键点。
后话
近几年,由于数据量的增长和算力的不断提升,知识图谱逐渐成为人工智能不可或缺的一环,知识图谱的研究角度和手段也日新月异,带时间标签的时序知识图谱和以事件为核心的事理知识图谱也进入了研究者的视界。最后,我们整理了几个基于知识图谱构建的网站供读者学习参考。
- [清华Aminer](https://www.aminer.cn/)
- [上海交大Acemap](https://www.acemap.info/)
- [复旦知识工场](http://kw.fudan.edu.cn/)
- [思知OwnThink](https://www.ownthink.com/)
- [中草药知识服务系统](http://zcy.ckcest.cn/tcm/)
- [北航中文知识图谱](http://www.actkg.com/linking/)
- [华东师范农业知识图谱](https://github.com/qq547276542/Agriculture_KnowledgeGraph)
参考
[1] Berners-Lee T, Hendler J, Lassila O. The semantic web[J]. Scientific american, 2001, 284(5): 34-43.
[2] https://baijiahao.baidu.com/s?id=1650526419042842719
[3] Wang Q, Mao Z, Wang B, et al. Knowledge graph embedding: A survey of approaches and applications[J]. IEEE Transactions on Knowledge and Data Engineering, 2017, 29(12): 2724-2743.
[4] https://archive.acemap.info/academic-report/knowledge-graph3
文章页脚扫一扫关注图灵技术域



