

摘要
研究人员通常只有在深入了解大量文献后才能提出新的想法。学术出版物的数量呈指数级增长,这一事实加剧了这一过程的困难。在本研究中,我们设计了一个基于概念共现的学术思想启发框架,该框架已集成到一个研究辅助系统DeepReport中。从我们的角度来看,在一篇学术论文中同时出现的两个概念(concept)的融合可以被视为一种新思想(idea)出现的重要方式。我们根据20个学科或主题概念的共现关系(co-occurrence),构造进化概念共现图(Evolving Concept Co-occurrence Graph)。然后,我们设计了一种基于掩蔽语言模型的时间链接预测方法,以探索不同概念之间的潜在联系。为了表达新发现的联系,我们还利用预先训练的语言模型,基于一种称为共现引用五元组(Co-occurrence Citation Quintuple)的新数据结构,生成对一个想法的描述。我们使用机器度量和人工评估来评估我们提出的系统。研究结果表明,我们的系统具有广阔的前景,可以帮助研究人员加快发现新想法的过程。
背景
我们大概是在21年年末的时候开展了这样一个课题,当时我们考虑到现有的学术界中:
1. 开箱即用(out-of-box)和跨学科(interdisciplinary)的科学工作可以得到科学资助者、行业和公众的更多关注。并且交叉领域的研究变得越来越重要,但是这些交叉领域的研究往往被大企业和政府垄断着。
2. 对于大多数研究人员🧑🏻🎓来说,提出新的idea需要花费大量时间。学术出版物的数量呈指数级增长,独立研究人员很难彻底通透这些论文。
3. 研究人员往往专注于他们专业但狭窄的领域,这使得他们的学术视野受限。
因此在这项工作中,我们的目的是揭示不同学术概念之间的深刻联系,同时激发研究人员对潜在学术思想的探索。
我们的两个主要目标是🌟idea探索(idea exploration)以及将🌟idea用语言表述(idea verbalization)出来。
Idea Exploration (探索)
对于idea的探索,有这样一个现代作家Maria Popova,她说了这样一句话:
In order for us to truly create and contribute to the world, we have to be able to connect countless dots, to cross-pollinate ideas from a wealth of disciplines, to combine and recombine these pieces and build new castles.
大体上的意思是强调了通过连接不同领域的知识、交叉汲取思想,并将它们重新组合来建立新事物的重要性。
比如,我们都知道交大有生物医学工程学院,它将工程学原理应用于医学和生物学问题的解决上。同样的,国家自然科学基金委员会前年也成立了交叉学部,展示了跨学科合作的重要性。
更具体来说,在人工智能领域,我列出了这样6个概念,他们之间的关联可以产生出这么多种概念,例如GNN和Transformer可以结合成Graph Transformer。
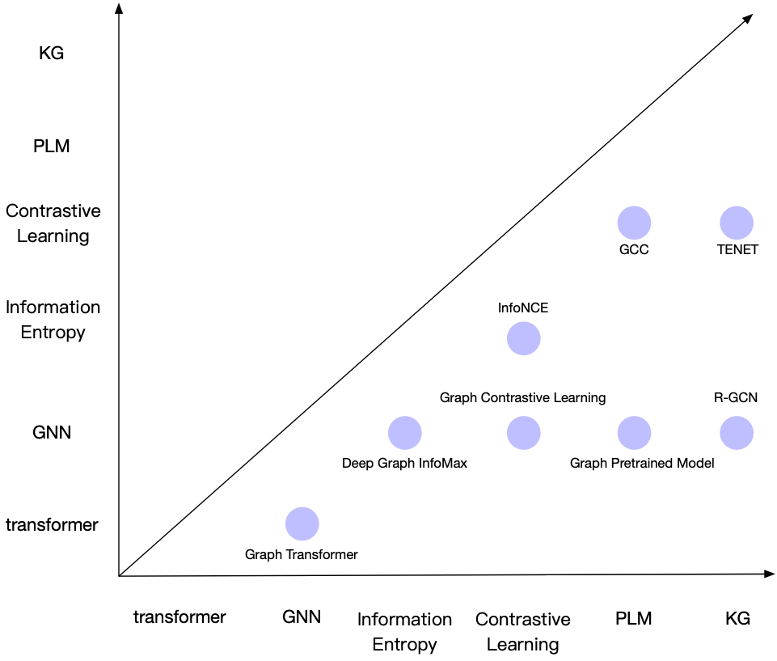
(应该强调的是,现实世界中存在着许多产生新思想的因素。我们只是提供了一种可能的方法作为初步探索。)
这种思路成为了idea探索的一个重要方向。此时idea的发现可以简化为找到未来可能存在的新的概念联系。也就是一种时序链接预测(temporal link prediction)问题。
我们提出了进化概念共现图(Evolving Concept Co-occurrence Graph),它是一种时序图,每一个时间点存储了概念的共现关系(co-occurrence)。这种共现关系很好理解,如果一篇论文中同时出现了A和B两个概念,那么我们可以认为这两个概念具有共现关系。
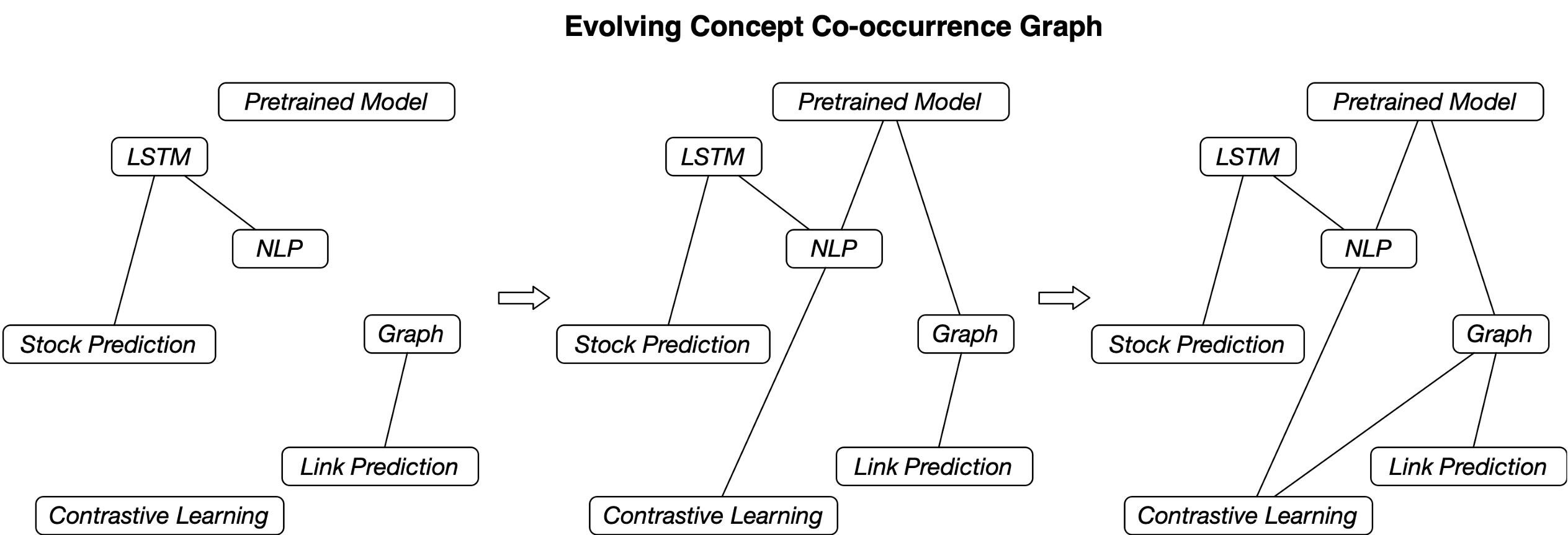
上图展示的是一个概念共现图的例子,随着时间的流逝,不同概念之间逐渐产生了关联。
需要指出的是概念共现图是一种严格进化的网络,在我们的建模中,它边的数量只会增加不会减少。但是在现实社会中,往往可能出现新的概念,也就是新的节点,因此传统的时序图链接预测的方法很难处理这种情况,此时需要考虑到节点的文本语义信息,这就需要用到语言模型。
由于当时生成式模型还没现在这么火,所以我们采用了传统的基于掩码建模的语言模型,通过时序采样+文本提示的方法将图结构转成以边为单位的语言描述序列。下图给出了一个示例,LSTM和股票预测在过去时间段里存在一条边,我们构建出这样一个序列,LSTM is related to stock prediction。这是一个正样本序列,其中前面的existing是时序标签,代表过去存在一条边,其他情况:包括当前边刚出现,或者未来存在一条边则用unknown表示。对于负样本序列,也就是我们需要构建出一个不存在连边的关系,那么我们用unrelated表示。
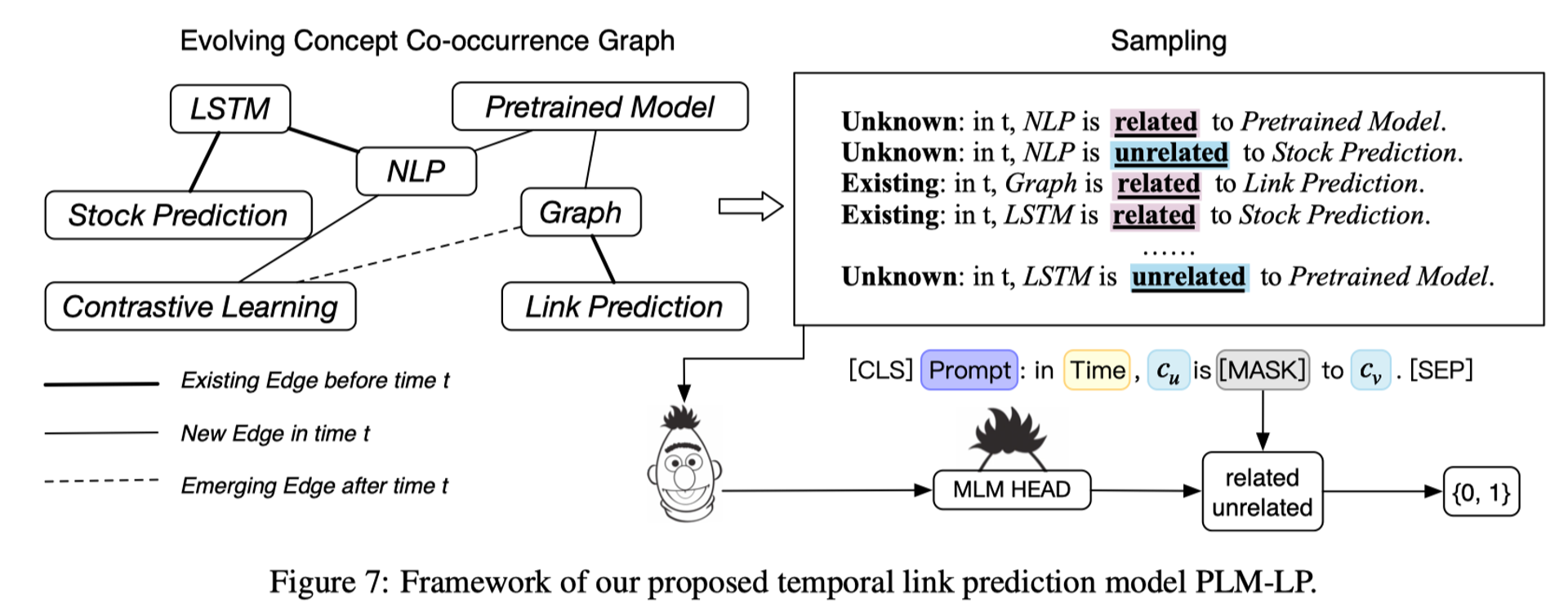
除此以外,对于正负样本的采样比例,也需要控制,因为图是稀疏的,如果每两个概念都采样,那么会导致负样本大大增加,因此,我们负样本只采样最难判断的样本,例如某个中心节点的k跳邻居,如果它在未来一段时间没有与中心节点相连,则采样为负样本。通过这种方式我们训练Bert来判断related还是unrelated,这样就实现了链接预测模型的训练,用来发现未来新的知识概念联系。
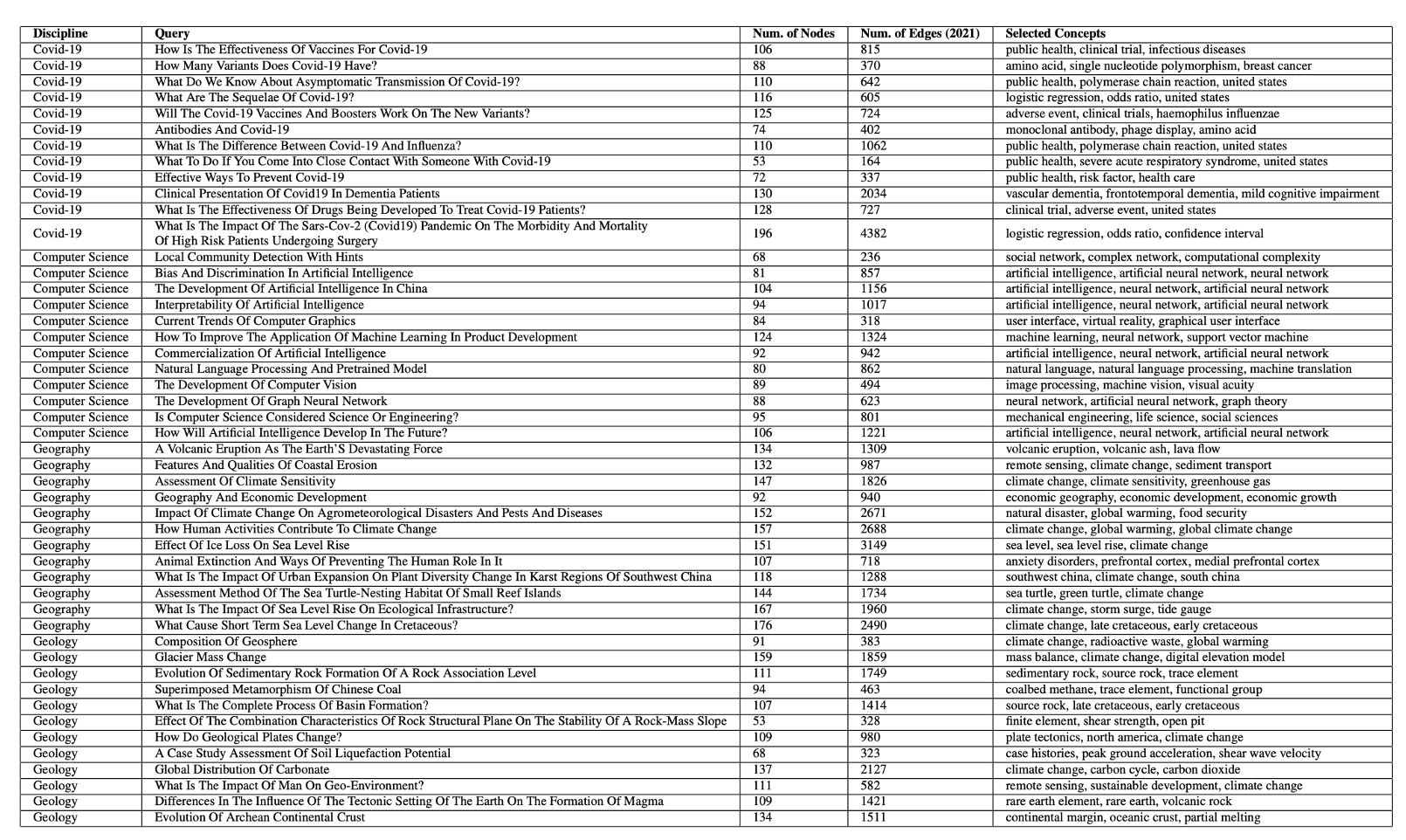
我们从19个学科和一个特殊主题(COVID-19)中收集了240个基本和常见的查询,并使用文本检索引擎Elasticsearch从2000年到2021年检索了最相关的论文。然后,我们使用信息提取工具(包括AutoPhrase)来识别概念。只有出现在我们数据库中的高质量概念才会被保留。最后,我们构建了240个不断发展的概念共现图,每个图包含22个快照(2000年到2021)。
Idea Verbalization (表达)
除此以外,另一个目标就是将上述概念用语言文字表达出来,于是我们提出了一种新的数据结构叫做共现引用五元组(Co-occurrence Citation Quintuple)。这是一种新的数据结构,用于描述概念之间的共现关系。它由五个元素组成:p是目标论文,它包含两个概念,c_u和c_v,这个包含的意思是指。论文中提到了这两个概念。此外,论文p引用了论文p_i和论文p_j,论文p_i则包含了概念c_u,论文p_j包含了概念c_v。这里的一个例子是论文p中提到了对比学习在文本摘要中的应用,而它引用的论文p_i介绍了文本摘要,引用的论文p_j则介绍了对比学习。
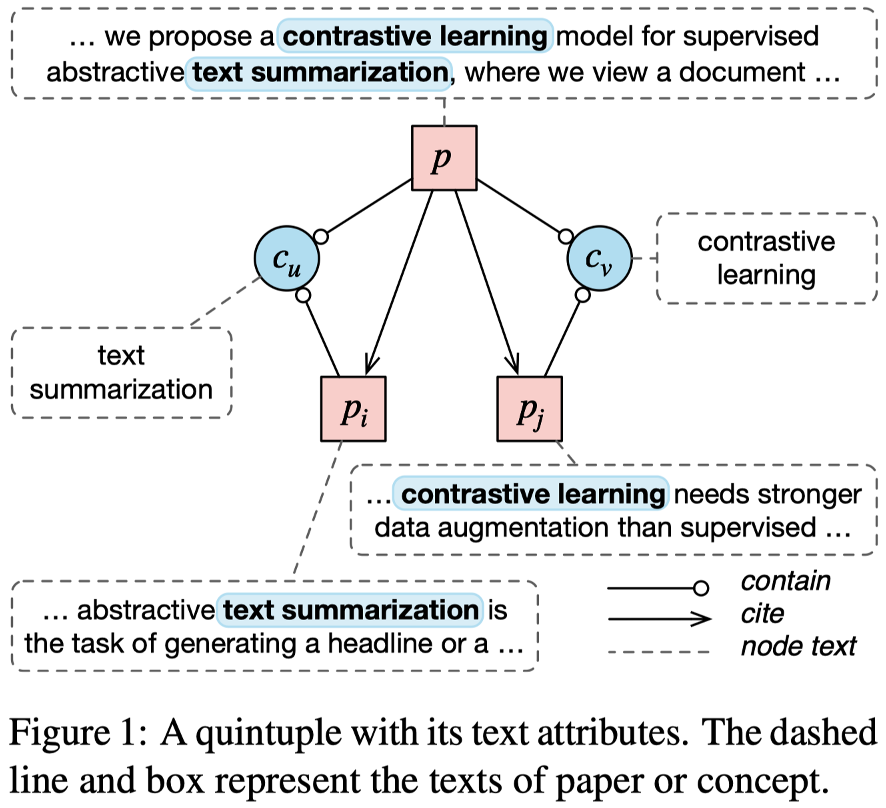
我们构建了一个大规模的共现引用五元组数据集。具体来说,我们首先选取了高引论文集合,并从这些论文的摘要中识别出不同的概念,然后利用Acemap的引用关系,获取符合条件的五元组数据集。
我们可以根据这样一种共现引用五元组,放到大语言模型中进行训练,给大模型提供SFT也就是有监督训练的数据,来引导大模型生成新的知识。我们将除p以外的其他元素作为输入,目标是输出p。这样,利用高质量的论文来预测未来可能出现的概念碰撞点,生成包含新知识的文本。
目前我们最新版的数据集中从19个学科搜集了超过五百三十四万条五元组数据(下表),超过了论文中一开始使用数据的五十多倍。
| Discipline | Quintuple | Concept | Concept Pair | Total p | Total p_i & p_j |
|---|---|---|---|---|---|
| Art | 7,510 | 2,671 | 5,845 | 2,770 | 7,060 |
| History | 5,287 | 2,198 | 4,654 | 2,348 | 5,764 |
| Philosophy | 45,752 | 4,773 | 25,935 | 16,896 | 29,942 |
| Sociology | 16,017 | 4,054 | 12,796 | 7,066 | 16,416 |
| Political Science | 67,975 | 6,105 | 42,411 | 26,198 | 53,933 |
| Business | 205,297 | 9,608 | 99,329 | 62,332 | 112,736 |
| Geography | 191,958 | 12,029 | 118,563 | 42,317 | 112,909 |
| Engineering | 506,635 | 16,992 | 249,935 | 137,164 | 273,894 |
| Geology | 365,183 | 13,795 | 190,002 | 98,991 | 222,358 |
| Medicine | 168,697 | 13,014 | 114,104 | 42,535 | 138,973 |
| Economics | 227,530 | 9,461 | 113,527 | 68,607 | 131,387 |
| Physics | 267,532 | 10,831 | 133,079 | 84,824 | 176,741 |
| Biology | 224,722 | 15,119 | 145,088 | 59,210 | 189,281 |
| Mathematics | 312,670 | 17,751 | 190,734 | 95,951 | 218,697 |
| Psychology | 476,342 | 9,512 | 194,038 | 115,725 | 212,180 |
| Computer Science | 531,654 | 16,591 | 244,567 | 151,809 | 238,091 |
| Environmental Science | 583,466 | 11,002 | 226,671 | 94,474 | 201,330 |
| Materials Science | 573,032 | 17,098 | 249,251 | 145,068 | 313,657 |
| Chemistry | 565,307 | 13,858 | 231,062 | 108,637 | 286,593 |
| Total | 5,342,566 | 206,462 | 2,591,591 | 1,362,922 | 2,941,942 |
评估
我们使用了机器度量和人工评估来评估我们提出的系统。我们采用传统的混淆矩阵来评估模型在进化概念共现图上的性能。
我们分成了两部分的预测,一部分是2021年所有的节点预测,另一部分只预测新边的结果。可以看到,所有这些模型都能够识别2021年存在的大多数边,但GCN-GAN和EvolveGCN在2021年发现新边时表现不佳。我们认为这是因为大多数图都是稀疏的,从而导致其他模型的过拟合。在我们的知识发现场景中,发现新边才是最重要的。

我们采用图灵测试+案例分析的方法来验证生成模型的效果。
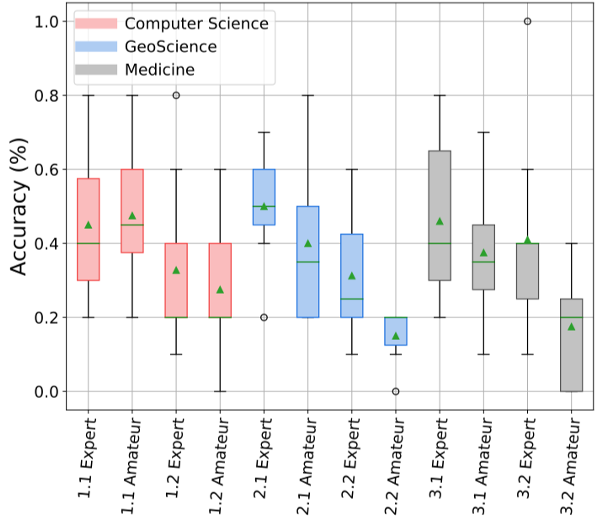
我们招募了更多计算机科学、地质科学(地质学和地理学)和医学领域的领域专家和非专家来进行图灵测试。专家包括教授、讲师、博士后研究人员和研究生(每个学科至少有两名教授)。参与者被要求阅读机器生成的输出和人工书写的文本,并从一组N中选择真正的人工书写文本。每个参与者在测试前都会得到指示。我们还允许参与者在测试期间使用互联网检索技术术语。对于每个学科,有两种不同的选择题模式,一种是每道题包含两个选项,另一种是每个题包含三个选项。图灵测试结果如下:
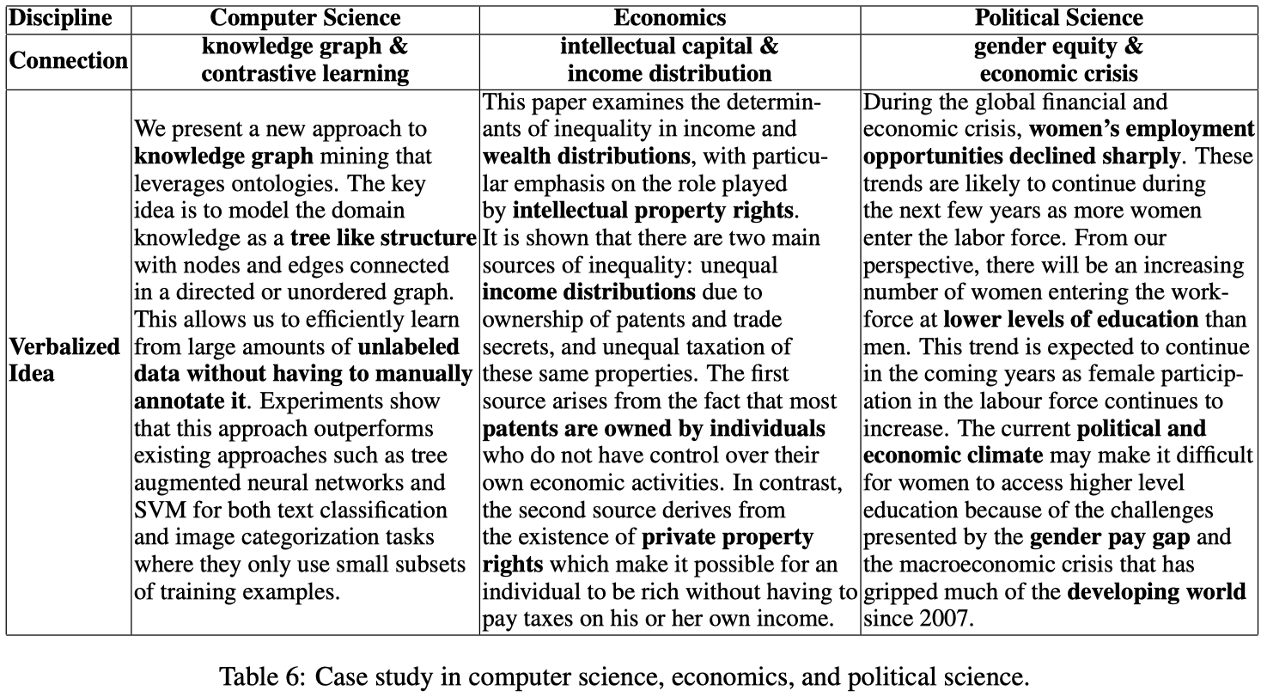
我们的案例研究分别涉及计算机科学、经济学和政治学。在第一个案例中,我们发现了一种新的概念共现关系,即“知识图谱”和“对比学习”,并生成了一个基于共现引用五元组的思想描述。在第二个案例中,我们发现知识产权与收入分配密切相关,并生成了一个基于共现引用五元组的思想描述。在最后一个案例中,我们发现发展中国家存在性别薪酬差距,尤其是在经济危机期间,我们也生成了一个基于共现引用五元组的思想描述。这些案例研究表明,我们的系统可以很好地预测和表达新的概念共现关系,并且生成的结果与人类直觉和价值观相一致。
DeepReport
根据以上技术和目标,我们开发了DeepReport知识发现研究辅助系统系统,可以访问idea.acemap.cn来试用。
这是我们第一版的pipeline,它主要包含三个模块:
- 数据检索和图构建模块
- 时序链接预测模块
- idea生成模块
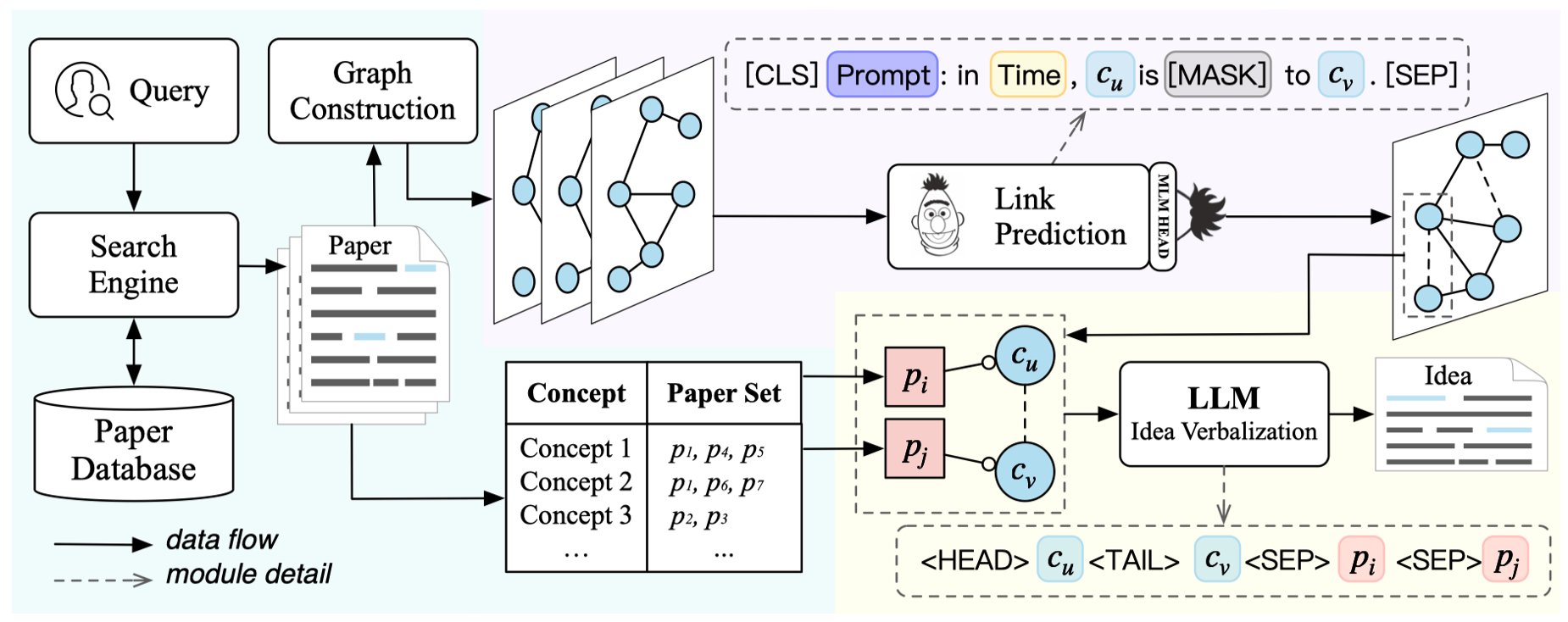
它首先接收用户的查询,并从数据库中检索最相关的论文,实时构建一个进化概念共现图。同时,系统维护两个字典,用于存储论文和概念之间的映射关系。然后,基于Bert的时间模型预测了c_u和c_v等概念的潜在连接,这可以看作是一个新的想法。最后,这些相互关联的概念,以及存储在上述词典中的论文中与之对应的句子,被输入到我们预训练的模型中,以表达一个想法。当然我们的模型还有优化的空间,我们目前打算是把Bert链接预测替换成生成式大模型的链接预测。
2023年年中,DeepReport系统进行了重大更新,包括数据和模型改进。在数据方面,我们引入了新版本的五元组数据(V202306),从而提高了质量和更大规模的数据集。
此外,我们在一个专业领域训练了一个新的最先进的模型。该模型与OpenAI接口的集成旨在提高我们在线服务的质量。我们专有的大规模模型的融合和OpenAI资源的整合使我们的系统能够提供卓越的性能,更好地满足用户的需求。
改进的五元组数据集的引入,加上新的专业领域模型的部署和openAI接口的使用,标志着我们的DeepReport系统取得了重大进展。这些更新使我们能够提供更准确可靠的结果,从而增强整体用户体验。我们仍然致力于进一步完善我们的系统,以确保它继续满足用户不断变化的需求。
总结
总之,本文提出了一种基于概念共现的学术思想启发框架,该框架已经被整合到一个研究助手系统中。我们构建了不断发展的概念共现图,并使用基于掩码语言模型的时间链接预测方法来探索不同概念之间的潜在联系。为了表达新发现的联系,我们利用预训练的语言模型生成了一个基于共现引用五元组的思想描述。我们的系统已经通过自动度量和人工评估进行了评估。我们相信,这个系统可以帮助研究人员更快地发现新思想,并在学术研究中发挥重要作用。未来,我们将继续改进我们的系统,包括扩展数据集、改进概念提取工具、优化时间链接预测方法,其中最终要的是,我们将采用大语言模型来训练多种知识发现任务,完成上述两个目标。
引用
该工作已发表至ACL 2023
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
@inproceedings{xu-etal-2023-exploring, title = "Exploring and Verbalizing Academic Ideas by Concept Co-occurrence", author = "Xu, Yi and Sheng, Shuqian and Xue, Bo and Fu, Luoyi and Wang, Xinbing and Zhou, Chenghu", booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)", month = jul, year = "2023", address = "Toronto, Canada", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2023.acl-long.727", doi = "10.18653/v1/2023.acl-long.727", pages = "13001--13027", } |
论文地址:https://aclanthology.org/2023.acl-long.727/
数据集地址:https://github.com/xyjigsaw/Kiscovery
更多内容访问 [omegaxyz.com](https://www.omegaxyz.com)
网站所有代码采用Apache 2.0授权
网站文章采用知识共享许可协议BY-NC-SA4.0授权
© 2023 • OmegaXYZ-版权所有 转载请注明出处



