

ACM-IEEE-arXiv Info Spider (开发中)
此项目的目的是从数字图书馆中抓取论文的结构化信息,这些信息可以用来进行学者分析,构建知识图谱等。
代码地址:https://github.com/xyjigsaw/ACM-IEEE-arXiv-Spider
支持的数据库
- ACM (已完成,Support Digital Library Search Result)
- IEEE (开发中,Support Single Page)
- arXiv (已完成,Support All Categories)
- AAAI (已完成,Support 2009-2019 AAAI Conferences)
关键词: Python, Scrapy, MySQL, Papers
依赖
- Python 3.6
- MySQL 8.0.17
- scrapy
- selenium
- PhantomJS (optional only for IEEE_Spider)
- scrapy_proxies
- logging
- re
- pymysql
- twisted
- json
- fake_useragent
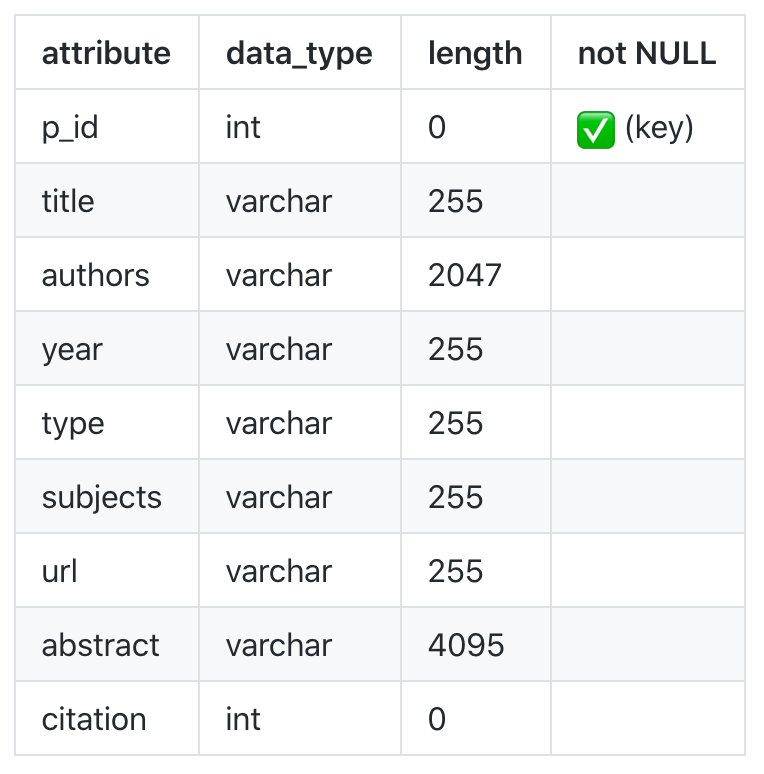
数据库与数据结构
你可以执行 papers.sql 来初始化数据库。
MYSQL_DBNAME = 'papers'
TABLE_NAME = {'ACM_Data', 'IEEE_Data', 'arXiv_Data'}
特性
1. 一个脚本自动运行,以获得免费的代理(仅HTTP),并将很快集成到基于剪贴的主程序。
2. 对于每个请求,它将生成一个随机的代理和用户代理。
3.提供了TXT文件、原始json(不是确切的json)和MySQL来存储数据。
4. 给出了基于层的可选日志。
5. 采用异步模式作为MySQL管道的数据存储机制,解决爬行器数据泛滥的问题,提高了程序的运行效率和可靠性。
安装与运行
在您启动scrapy之前,您应该首先自定义设置。
当您启动IEEE_Spider时,需要添加基于selenium和PhantomJS的js中间件。
终端
|
1 |
scrapy crawl ACM_Spider |
或者
|
1 |
scrapy crawl IEEE_Spider |
...
即将开发
- IEEE Spider (The HTML is JS-dynamic.)
- arXix (easy)
- Proxy Downloader Integration
- MongoDB Storage
- Robuster Xpath Rules
- UUID for Database
- Crawl Specific Pages
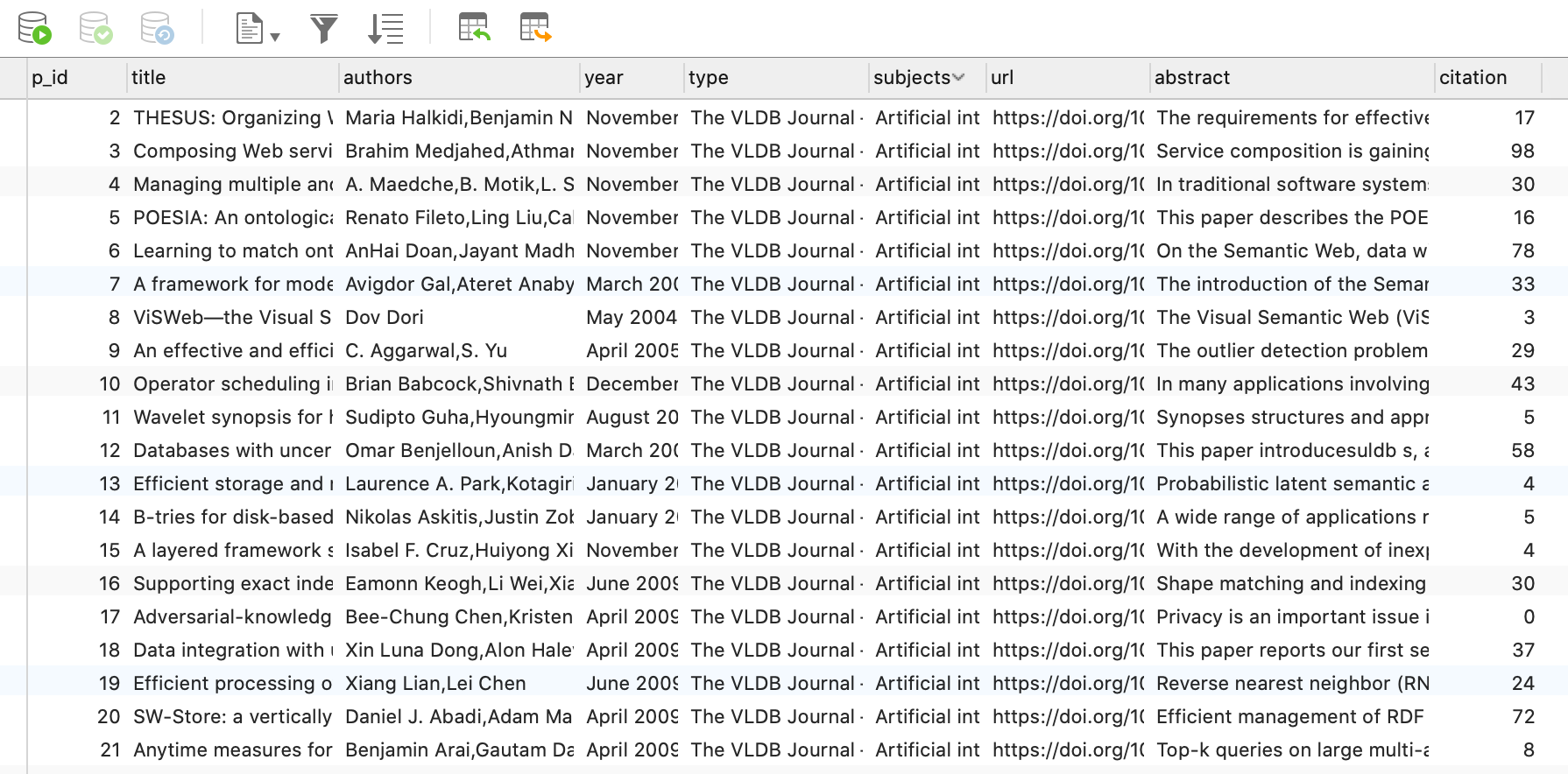
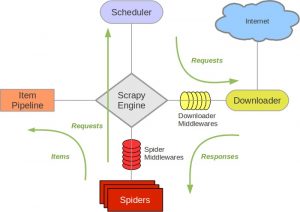
数据预览


感谢博主的分享。我在运行时遇到一点问题,能否请您解惑。我在获取代理列表时提示:“由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。”请问这个问题如何解决,或者有什么解决思路吗,望解惑,十分感谢!
了解,这个可能是代理站点服务器出现了问题,可以将middleware的代理服务注释掉,后续我会更新,请关注
博主您好,能否给个qq,关于这个爬虫有点问题想咨询下,拜托了,谢谢
你好可以在github上提出issue哦
这个爬虫太需要了。请问能不能多解释一下“启动scrapy之前的自定义设置”?是不是只需要在 settings.py 里面填入地址即可?还是middlewares.py也需要设置?
你只需要配置setting.py的 URL、Database和PROXY_LIST(可选),这个文件是scrapy自动生成的,具体的网上有教程。middleware是用来反反爬虫的,一个是RandomUserAgentMiddleware另一个是JSMiddleware,这两个你不需要手动配置,也可以直接忽略掉。