Scrapy组成
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
- 引擎(Scrapy):用来处理整个系统的数据流,触发事务(框架核心)。
- 调度器(Scheduler):用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader):用于下载网页内容,并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders):爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares):位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares):介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middewares):介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
Scrapy创建
安装好scrapy类库之后,就可以创建scrapy项目了,pycharm不能直接创建scrapy项目,必须通过命令行创建,打开pycharm的Terminal终端,输入scrapy startproject scrapy_demo命令。需要注意的是,环境变量必须要配好才能在cmd中显示scrapy命令.
对于Mac,由于Mac的python有多个版本,如果使用3.6的版本,不能直接在命令行运行scrapy,需要创建软链接(注意对应的版本)。
|
1 |
ln -s /Library/Frameworks/Python.framework/Versions/3.6/bin/scrapy /usr/local/bin/scrapy |
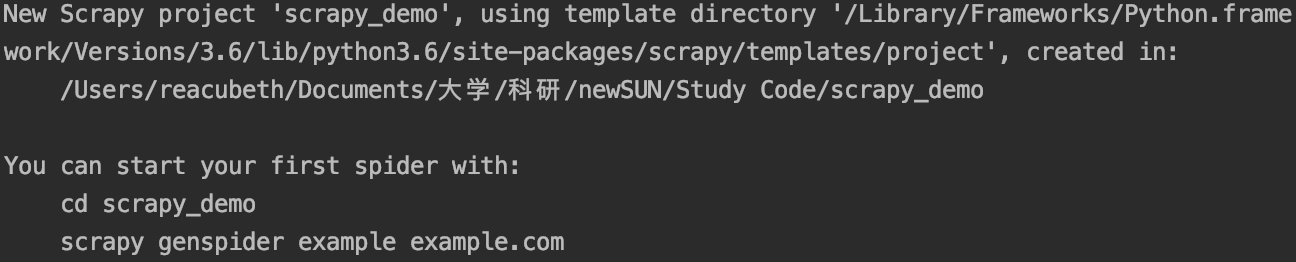
看到下面的信息则说明创建成功了。
此时可以看到项目自动创建了以下几个文件
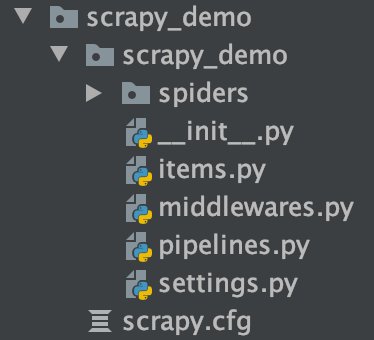
- scrapy.cfg: 项目的配置文件
- scrapy_demo/ :该项目的python模块,之后将在这里加入代码
- items.py:项目中的items文件,用来定义我们要抓取的数据
- middlewares.py:项目中的middlewares文件
- pipelines.py:项目中的pipelines文件,用来对spider返回的item列表进行数据的保存等操作,可以写入文件或保存到数据库
- setting.py:爬虫配置文件
- spiders/:放置spider代码的目录(自己编写)
scrapy网站爬取
接下来,将对IEEE和arXiv网站进行爬虫,其中middlewares.py,__init__.py文件保持默认。
①根据网站内容在item.py中定义爬取的数据结构
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html # 在items.py文件中定义我们要抓取的数据 import scrapy class ScrapyDemoItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() authors = scrapy.Field() subjects = scrapy.Field() # year = scrapy.Field() # type = scrapy.Field() # publisher = scrapy.Field() |
②在该目录的Spiders文件夹下面建立自己的爬虫
arXiv_Spider.py
需要注意的是难点是对于HTML元素的提取,此处不具体解释提取的代码如何编写。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
import scrapy import re from scrapy_demo.items import ScrapyDemoItem class arXivSpider(scrapy.Spider): name = "arXiv_Spider" allowed_domains = ["arxiv.org"] start_urls = ['https://arxiv.org/list/cs.AI/recent'] def parse(self, response): # get num line num = response.xpath('//*[@id="dlpage"]/small[1]/text()[1]').extract()[0] # get max_index max_index = int(re.search(r'\d+', num).group(0)) for index in range(1, max_index + 1): item = ScrapyDemoItem() # get title and clean data title = response.xpath('//*[@id="dlpage"]/dl/dd[' + str(index) + ']/div/div[1]/text()').extract() # remove blank char title = [i.strip() for i in title] # remove blank str title = [i for i in title if i is not ''] # insert title try: item['title'] = title[0] except IndexError: item['title'] = 'error' authors = '' # authors' father node xpath_fa = '//*[@id="dlpage"]/dl/dd[' + str(index) + ']/div/div[2]//a/text()' author_list = response.xpath(xpath_fa).getall() authors = str.join('', author_list) item['authors'] = authors item['subjects'] = response.xpath( 'string(//*[@id="dlpage"]/dl/dd[' + str(5) + ']/div/div[5]/span[2])').extract_first() yield item |
③配置settings.py
即将一些注释吊的部分根据自己的需要去掉注释并补充,这里我注释了一下几个内容:
设置用户代理,可以多设置几个,反爬虫:
|
1 |
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36' |
pipelines需要增加:
|
1 |
ITEM_PIPELINES = { 'scrapy_demo.pipelines.ScrapyDemoPipeline': 300, } |
完整的settings.py:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 |
# -*- coding: utf-8 -*- # Scrapy settings for scrapy_demo project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'scrapy_demo' SPIDER_MODULES = ['scrapy_demo.spiders'] NEWSPIDER_MODULE = 'scrapy_demo.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'scrapy_demo (+http://www.yourdomain.com)' USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36' # Obey robots.txt rules ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'scrapy_demo.middlewares.ScrapyDemoSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'scrapy_demo.middlewares.ScrapyDemoDownloaderMiddleware': 543, #} # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'scrapy_demo.pipelines.ScrapyDemoPipeline': 300, } # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' |
④在终端运行爬虫文件
|
1 |
scrapy crawl arXiv_Spider |
结果: