

对比学习
对比学习是一种通过对比正反两个例子来学习表征的自监督学习方法。对于自监督对比学习,下一个等式是对比损失:
![\[ \mathcal{L}_{i,j} = - \log \frac{exp(\textbf{z}_i \cdot \textbf{z}_j / \tau)}{\sum_{k=1,k\neq i}^{2N}exp(\textbf{z}_i \cdot \textbf{z}_k / \tau)} \]](https://www.omegaxyz.com/wp-content/ql-cache/quicklatex.com-4069a388d2125627d1c00663032736a0_l3.svg "Rendered by QuickLaTeX.com")
在很多情况下,对比学习只需要对每一个样本生成一个正样本,同一个batch内的其他样本作为负样本。
图像
在图像领域,正样本的设计是比较简单的,这里第一张是原图,其他图片都是通过旋转,剪裁,遮盖,加噪声等方式获得的正样本。因此,在图像领域,无监督的对比学习往往更容易训练。

NLP
在自然语言处理领域,也有很多增强正样本的方法,这是其中两种:
一种是同义词替换(Synonym substitution),我们可以通过bert或者word2vec找到在语义空间相近的单词,替换掉原来的词做数据增强。
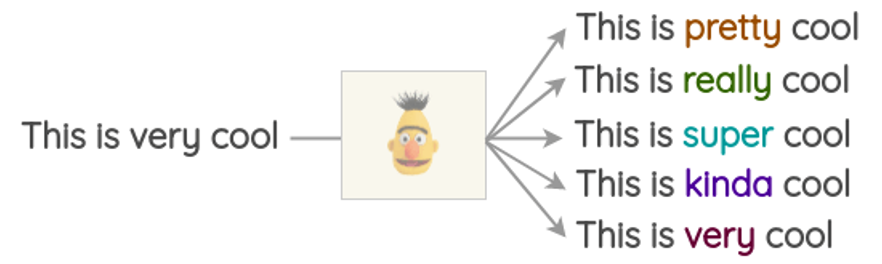

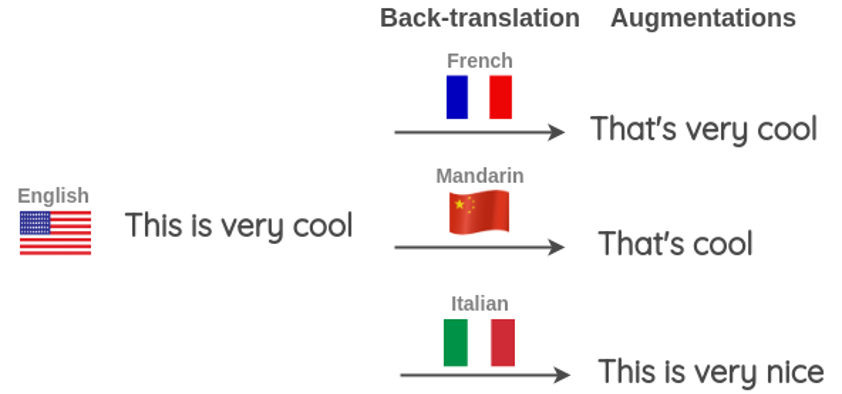
另一种技术叫做后翻译(Back-translation),比如我要做英文数据的增强,那么我可以用谷歌或者有道翻译成法文,中文等,然后再将法文中文翻译回英文。这样我也做到了数据增强。
Graph
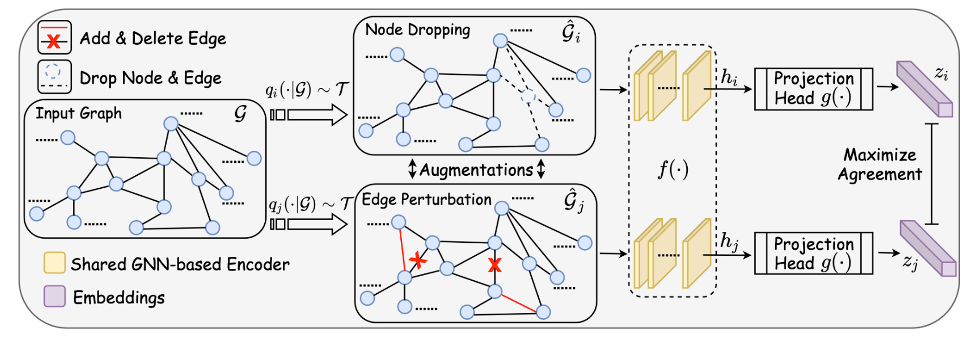
在graph领域,数据增强的方式就比较局限了,目前有几种主流的方法,去点,边扰动和特征shuffle。
例如我们可以将一些不太重要的节点从图中去掉,也可以通过邻域信息,启发式地做边扰动。
Knowledge Graph
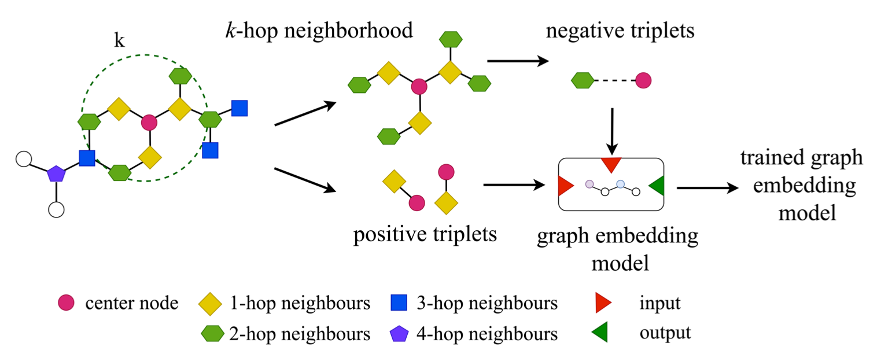
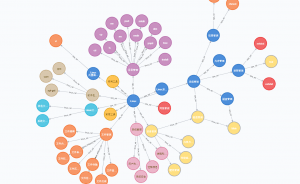
在知识图谱方面,鲜有基于对比学习的工作,目前找到了一篇,它用的是triplet loss,而不是主流的InfoNCE,而且他构造的是负样本,对于一个三元组,文章中采用K-阶的邻居作为负样本。比如对于这个红色的中心节点,它的一阶邻居,也就是黄色的节点是正样本,2-3-4阶的邻居由于没有边和红色的中间结点相连,因此可以作为负样本。
参考资料
[1] Ahrabian, Kian, et al. "Structure Aware Negative Sampling in Knowledge Graphs." EMNLP. 2020.
[2] You, Yuning, et al. "Graph contrastive learning with augmentations." Advances in Neural Information Processing Systems 33 (2020): 5812-5823.

啥也不说了,希望疫情早点结束吧!