简介
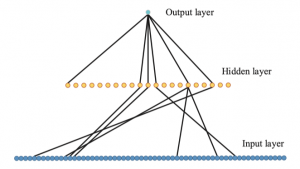
Word2vec,是为一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
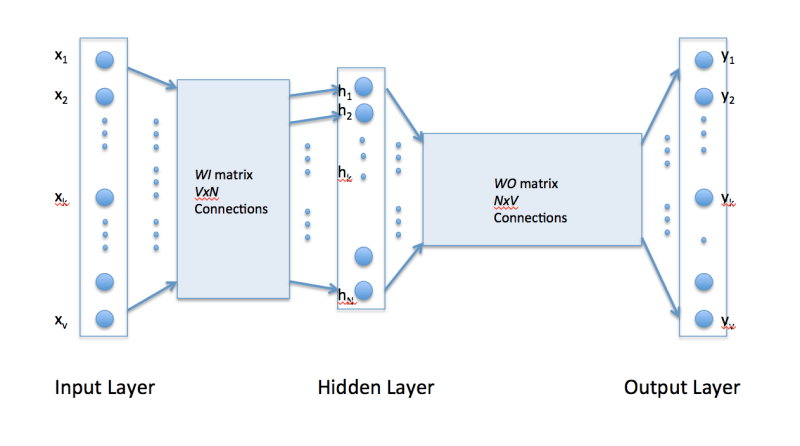
WI 的大小是VxN, V是单词字典的大小, 每次输入是一个单词, N是你设定的隐层大小。
One-hot编码
One hot representation用来表示词向量非常简单,但是却有很多问题。当单词数特别多时,会引起维度灾难。这样的向量其实除了一个位置是1,其余的位置全部都是0,表达的效率非常低。
one-hot编码python实现
Dristributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
词袋模型(Bag-of-words model)
- 从上下文来预测一个文字
词袋模型(Bag-of-words model)是个在自然语言处理和信息检索(IR)下被简化的表达模型。此模型下,像是句子或是文件这样的文字可以用一个袋子装着这些词的方式表现,这种表现方式不考虑文法以及词的顺序。最近词袋模型也被应用在计算机视觉领域。词袋模型被广泛应用在文件分类,词出现的频率可以用来当作训练分类器的特征。关于"词袋"这个用字的由来可追溯到泽里格·哈里斯于1954年在Distributional Structure的文章。
连续词袋模型(CBOW)
- 移除前向反馈神经网络中非线性的hidden layer,直接将中间层的embedding layer与输出层的softmax layer连接;
- 忽略上下文环境的序列信息:输入的所有词向量均汇总到同一个embedding layer;
- 将future words纳入上下文环境
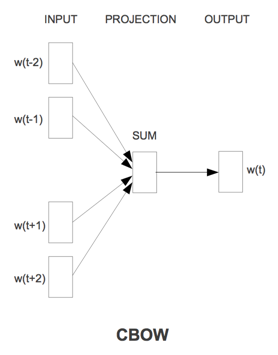
从数学上看,CBoW模型等价于一个词袋模型的向量乘以一个embedding矩阵,从而得到一个连续的embedding向量。这也是CBoW模型名称的由来。
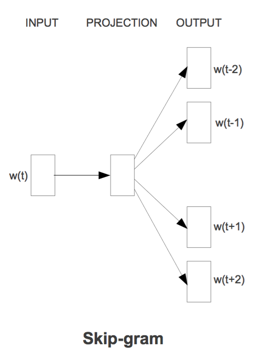
Skip-gram 模型
- 从一个文字来预测上下文
Skip-gram 模型是一个简单但却非常实用的模型。在自然语言处理中,语料的选取是一个相当重要的问题:
第一,语料必须充分。一方面词典的词量要足够大,另一方面要尽可能多地包含反映词语之间关系的句子,例如,只有“鱼在水中游”这种句式在语料中尽可能地多,模型才能够学习到该句中的语义和语法关系,这和人类学习自然语言一个道理,重复的次数多了,也就会模仿了;
第二,语料必须准确。 也就是说所选取的语料能够正确反映该语言的语义和语法关系,这一点似乎不难做到,例如中文里,《人民日报》的语料比较准确。 但是,更多的时候,并不是语料的选取引发了对准确性问题的担忧,而是处理的方法。 n元模型中,因为窗口大小的限制,导致超出窗口范围的词语与当前词之间的关系不能被正确地反映到模型之中,如果单纯扩大窗口大小又会增加训练的复杂度。Skip-gram 模型的提出很好地解决了这些问题。顾名思义,Skip-gram 就是“跳过某些符号”,例如,句子“中国足球踢得真是太烂了”有4个3元词组,分别是“中国足球踢得”、“足球踢得真是”、“踢得真是太烂”、“真是太烂了”,可是我们发现,这个句子的本意就是“中国足球太烂”可是上述 4个3元词组并不能反映出这个信息。Skip-gram 模型却允许某些词被跳过,因此可以组成“中国足球太烂”这个3元词组。 如果允许跳过2个词,即 2-Skip-gram。