文章目录
名称
论文的名称是Going Deeper with Convolutions,启发自“We need to go deeper.”出处先不说。
而论文提出的CNN算法名称是GoogLeNet,GoogLeNet是谷歌(Google)公司研究出来的深度神经网络结构,为什么不叫GoogleNet,而叫GoogLeNet,据说是为了向LeNet致敬,因此取名为GoogLeNet。
应用领域:图像识别与分类。
问题的提出与分析
动机和高层次的考虑
最直接提升性能的方法是提高SIZE,即增加深度与宽度。这是一种简单并且安全的训练高质量模型的方法,尤其是在大的有标签的训练集上。然而这个简单的方法有两个主要的缺陷。
- ①参数增加,数据不足的情况下容易导致过拟合
- ②计算资源要求高,而且在训练过程中会使得很多参数趋于0,浪费资源
解决方式
解决以上两个问题最基本的方法是使用稀疏连接代替完全连接层(fully-connected layers),甚至在卷积过程中也采用此方法。
理论依据
一个概率分布可以用一个大的稀疏的神经网络表示,最优的结构的构建通过分析上层的激活状态统计相关性,并把输出高度相关的神经元聚合。这与生物学中的Hebbian法则“某些神经元的反应基本一致,同时兴奋或者同时抑制”。
当然这样也是有问题的,计算机的基础结构在遇到系数数据计算是会很不高效,使用稀疏矩阵会使得效率大大降低。
目标:设计一个既能利用稀疏性,又可以保证计算资源的使用效率。
Inception模型
模型构成
Inception的命名https://knowyourmeme.com/memes/we-need-to-go-deeper
这句话最初是在科幻电影《盗梦空间》中出现的,《盗梦空间》的英文名即“Inception”而剧中人物多姆·科布(莱昂纳多·迪卡普里奥饰演)和罗伯特·费希尔(由西利安·墨菲饰演)讲述了在一个人的脑海里植入一个思想的故事。

开头所说的We need to go deeper也是电影《盗梦空间》中的一个表达,它通常使用电影中的屏幕截图来显示图像宏和垂直的多窗格。

原始的Inception版本V0:
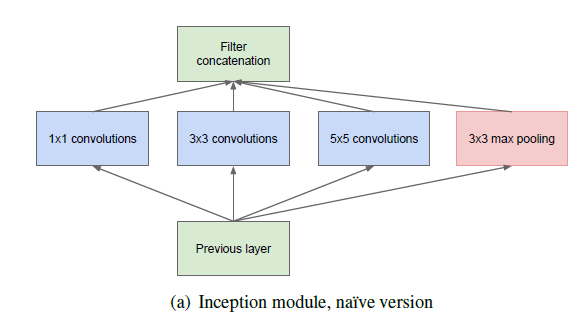
Inception的框架是作为一个案例研究开始的,评估复杂网络的假设输出来近似拓扑结构算法。
主要思想是考虑一个卷积vision网络的最优局部系数结构是如何近似和覆盖容易获得的密集部分。
该结构将常用的卷积(1x1,3x3,5x5)还有池化操作(3x3)堆叠在一起,需要注意的是卷积与池化后的尺寸相同,将通道增加。一方面增加了网络的宽度,另一方面增加了网络最尺度的适应性。
网络卷积层能够提取输入的每一个细节信息,同时5x5的滤波器也能够覆盖大部分接受层的输入。还可以进行池化操作,以减少空间大小降低过拟合,在这些层之上,每一个卷积层后都要做一个ReLu操作增加非线性特征。
为了减少卷积核的计算量需要在3x3,5x5之前还有最大池化之后加上一个1 x1的卷积核。这就出现了修正后的Inception V1
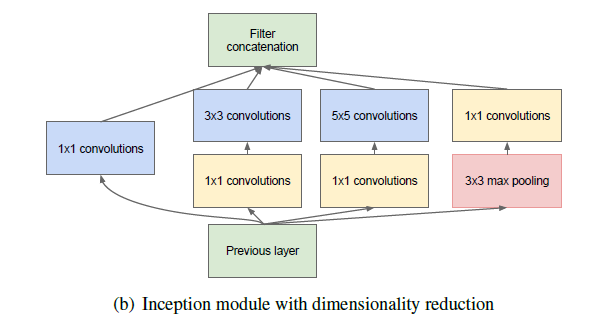
1x1卷积的主要目的是为了减少维度,还用于修正线性激活(ReLU)。比如,上一层的输出为100x100x128,经过具有256个通道的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256,其中,卷积层的参数为128x5x5x256= 819200。而假如上一层输出先经过具有32个通道的1x1卷积层,再经过具有256个输出的5x5卷积层,那么输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256= 204800,大约减少了4倍。
具体阐释
(1)GoogLeNet采用了模块化的结构(Inception结构),方便增添和修改;
(2)网络最后采用了average pooling(平均池化)来代替全连接层,该想法来自NIN(Network in Network),事实证明这样可以将准确率提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便对输出进行灵活调整;
(3)虽然移除了全连接,但是网络中依然使用了Dropout ;
(4)为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度(辅助分类器)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益。而在实际测试的时候,这两个额外的softmax会被去掉。
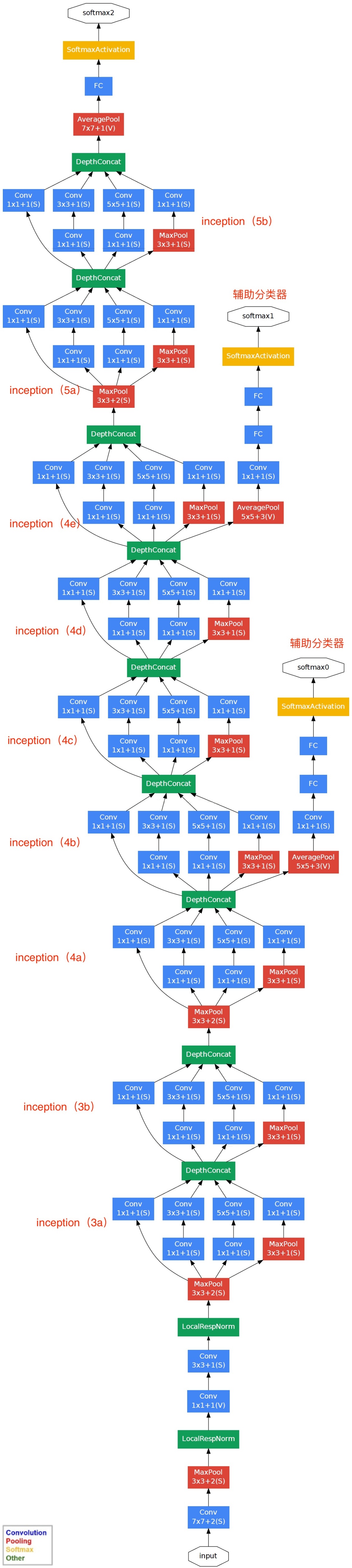
网络结构图细节如下
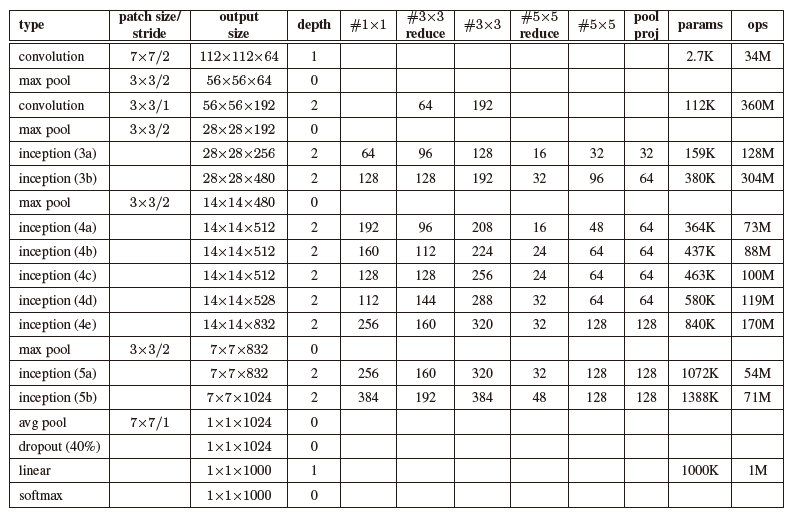
GoogLeNet总结构图及解析
GoogLeNet网络结构明细表解析如下
0、输入
原始输入图像为224x224x3,且都进行了零均值化的预处理操作(图像每个像素减去均值)。
1、第一层(卷积层)
使用7x7的卷积核(滑动步长2,padding为3),64通道,输出为112x112x64,卷积后进行ReLU操作
经过3x3的max pooling(步长为2),输出为((112 - 3+1)/2)+1=56,即56x56x64,再进行ReLU操作
2、第二层(卷积层)
使用3x3的卷积核(滑动步长为1,padding为1),192通道,输出为56x56x192,卷积后进行ReLU操作
经过3x3的max pooling(步长为2),输出为((56 - 3+1)/2)+1=28,即28x28x192,再进行ReLU操作
3a、第三层(Inception 3a层)
分为四个分支,采用不同尺度的卷积核来进行处理
(1)64个1x1的卷积核,然后RuLU,输出28x28x64
(2)96个1x1的卷积核,作为3x3卷积核之前的降维,变成28x28x96,然后进行ReLU计算,再进行128个3x3的卷积(padding为1),输出28x28x128
(3)16个1x1的卷积核,作为5x5卷积核之前的降维,变成28x28x16,进行ReLU计算后,再进行32个5x5的卷积(padding为2),输出28x28x32
(4)pool层,使用3x3的核(padding为1),输出28x28x192,然后进行32个1x1的卷积,输出28x28x32。
将四个结果进行连接,对这四部分输出结果的第三维并联,即64+128+32+32=256,最终输出28x28x256
3b、第三层(Inception 3b层)
(1)128个1x1的卷积核,然后RuLU,输出28x28x128
(2)128个1x1的卷积核,作为3x3卷积核之前的降维,变成28x28x128,进行ReLU,再进行192个3x3的卷积(padding为1),输出28x28x192
(3)32个1x1的卷积核,作为5x5卷积核之前的降维,变成28x28x32,进行ReLU计算后,再进行96个5x5的卷积(padding为2),输出28x28x96
(4)pool层,使用3x3的核(padding为1),输出28x28x256,然后进行64个1x1的卷积,输出28x28x64。
将四个结果进行连接,对这四部分输出结果的第三维并联,即128+192+96+64=480,最终输出输出为28x28x480
第四层(4a,4b,4c,4d,4e)、第五层(5a,5b)……,与3a、3b类似,在此就不再重复。