

在概率论和信息论中,两个随机变量的互信息(Mutual Information,简称MI)或转移信息(transinformation)是变量间相互依赖性的量度。不同于相关系数,互信息并不局限于实值随机变量,它更加一般且决定着联合分布 p(X,Y) 和分解的边缘分布的乘积 p(X)p(Y) 的相似程度。互信息(Mutual Information)是度量两个事件集合之间的相关性(mutual dependence)。互信息最常用的单位是bit。
互信息的定义
正式地,两个离散随机变量 X 和 Y 的互信息可以定义为:
其中 p(x,y) 是 X 和 Y 的联合概率分布函数,而p(x)和p(y)分别是 X 和 Y 的边缘概率分布函数。
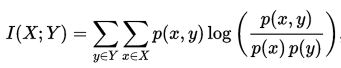
在连续随机变量的情形下,求和被替换成了二重定积分:
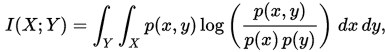
其中 p(x,y) 当前是 X 和 Y 的联合概率密度函数,而p(x)和p(y)分别是 X 和 Y 的边缘概率密度函数。
互信息量I(xi;yj)在联合概率空间P(XY)中的统计平均值。 平均互信息I(X;Y)克服了互信息量I(xi;yj)的随机性,成为一个确定的量。如果对数以 2 为基底,互信息的单位是bit。
直观上,互信息度量 X 和 Y 共享的信息:它度量知道这两个变量其中一个,对另一个不确定度减少的程度。例如,如果 X 和 Y 相互独立,则知道 X 不对 Y 提供任何信息,反之亦然,所以它们的互信息为零。在另一个极端,如果 X 是 Y 的一个确定性函数,且 Y 也是 X 的一个确定性函数,那么传递的所有信息被 X 和 Y 共享:知道 X 决定 Y 的值,反之亦然。因此,在此情形互信息与 Y(或 X)单独包含的不确定度相同,称作 Y(或 X)的熵。而且,这个互信息与 X 的熵和 Y 的熵相同。(这种情形的一个非常特殊的情况是当 X 和 Y 为相同随机变量时。)
互信息是 X 和 Y 联合分布相对于假定 X 和 Y 独立情况下的联合分布之间的内在依赖性。于是互信息以下面方式度量依赖性:I(X; Y) = 0 当且仅当 X 和 Y 为独立随机变量。从一个方向很容易看出:当 X 和 Y 独立时,p(x,y) = p(x) p(y),因此:
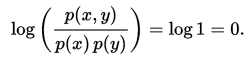
此外,互信息是非负的(即 I(X;Y) ≥ 0; 见下文),而且是对称的(即 I(X;Y) = I(Y;X))。
更多互信息内容请访问:http://www.omegaxyz.com/2018/08/02/mi/
互信息特征选择算法的步骤
- ①划分数据集
- ②利用互信息对特征进行排序
- ③选择前n个特征利用SVM进行训练
- ④在测试集上评价特征子集计算错误率
缺点
此种特征选择方法是最大化特征与分类变量之间的相关度,就是选择与分类变量拥有最高相关度的前k个变量。但是,在特征选择中,单个好的特征的组合并不能增加分类器的性能,因为有可能特征之间是高度相关的,这就导致了特征变量的冗余。
代码
注意使用的数据集是dlbcl,大概五千多维,可以从UCI上下载,最终选择前100特征进行训练。
主函数代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
clear all close all clc; [X_train,Y_train,X_test,Y_test] = divide_dlbcl(); Y_train(Y_train==0)=-1; Y_test(Y_test==0)=-1; % number of features numF = size(X_train,2); [ ranking , w] = mutInfFS( X_train, Y_train, numF ); k = 100; % select the Top 2 features svmStruct = svmtrain(X_train(:,ranking(1:k)),Y_train,'showplot',true); C = svmclassify(svmStruct,X_test(:,ranking(1:k)),'showplot',true); err_rate = sum(Y_test~= C)/size(X_test,1); % mis-classification rate conMat = confusionmat(Y_test,C); % the confusion matrix fprintf('\nAccuracy: %.2f%%, Error-Rate: %.2f \n',100*(1-err_rate),err_rate); |
mutInfFS.m
|
1 2 3 4 5 6 7 8 9 10 |
function [ rank , w] = mutInfFS( X,Y,numF ) rank = []; for i = 1:size(X,2) rank = [rank; -muteinf(X(:,i),Y) i]; end; rank = sortrows(rank,1); w = rank(1:numF, 1); rank = rank(1:numF, 2); end |
muteinf.m
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
function info = muteinf(A, Y) n = size(A,1);%实例数量 Z = [A Y];%所有实例的维度值及标签 if(n/10 > 20) nbins = 20; else nbins = max(floor(n/10),10);%设置区间的个数 end; pA = hist(A, nbins);%min(A)到max(A)划分出nbins个区间出来,求每个区间的概率 pA = pA ./ n;%除以实例数量 i = find(pA == 0); pA(i) = 0.00001;%不能使某一区间的概率为0 od = size(Y,2);%一个维度 cl = od; %下面是求实例不同标签的的概率值,也就是频率 if(od == 1) pY = [length(find(Y==+1)) length(find(Y==-1))] / n; cl = 2; else pY = zeros(1,od); for i=1:od pY(i) = length(find(Y==+1)); end; pY = pY / n; end; p = zeros(cl,nbins); rx = abs(max(A) - min(A)) / nbins;%每个区间长度 for i = 1:cl xl = min(A);%变量的下界 for j = 1:nbins if(i == 2) && (od == 1) interval = (xl <= Z(:,1)) & (Z(:,2) == -1); else interval = (xl <= Z(:,1)) & (Z(:,i+1) == +1); end; if(j < nbins) interval = interval & (Z(:,1) < xl + rx); end; %find(interval) p(i,j) = length(find(interval)); if p(i,j) == 0 % hack! p(i,j) = 0.00001; end xl = xl + rx; end; end; HA = -sum(pA .* log(pA));%计算当前维度的信息熵 HY = -sum(pY .* log(pY));%计算标签的信息熵 pA = repmat(pA,cl,1); pY = repmat(pY',1,nbins); p = p ./ n; info = sum(sum(p .* log(p ./ (pA .* pY)))); info = 2 * info ./ (HA + HY);%计算互信息 |
前100个特征的效果:
Accuracy: 86.36%, Error-Rate: 0.14
选择前两个特征进行训练(压缩率接近100%,把上述代码中的K设为2即可)的二维图:
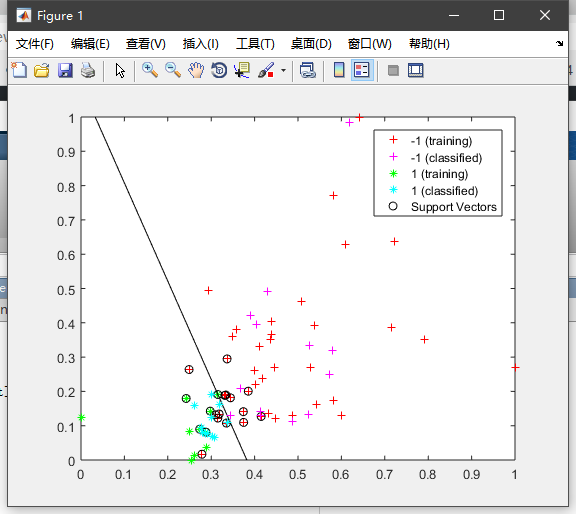
Accuracy: 75.00%, Error-Rate: 0.25
数据集:https://github.com/xyjigsaw/Dataset


请问info是互信息,第二行代码是不是用于将互信息归一化为[0,1]?
info = sum(sum(p .* log(p ./ (pA .* pY))));
info = 2 * info ./ (HA + HY);%计算互信息
您好,请问最后两张图是如何做出来的?我用的基本方式没出来图
你好,这三个文件同时保存到本地可以生成最后一张图。
您好,方便发一下dlbcl的数据集吗?github上面那个打不开,请博主发一份yq13835520722@163.com,非常感谢!!
请问可以提供dlbcl数据集吗?谢谢,1040634393@qq.com.
可以的,数据集已经上传到https://github.com/xyjigsaw/Dataset
我想问下,我的数据是有文本和数字的,这个人是A类人,影响因素有男/女,学历(高中/本科/研究生),民族(汉/藏/。。。),年龄(56),这样的混合数据怎么处理呢,我看你自己用的那个数据集都是数字
我想看看这些因素是如何影响这个人的类型的,比如有A,B,C,D四类,这些因素不同可以导致这个人的类型不同,然后计算相关性
特征离散化
博主还在吗。。。可以给我发一份数据集吗?1160788784@qq.com 万分感谢!
是想要dlbcl的数据集,谢谢博主!
在这个里面,https://github.com/xyjigsaw/Dataset
rank = [rank; -muteinf(X(:,i),Y) i];这个地方的-muteinf(X(:,i),Y) i代码是不是有错误啊??
麻烦可以提供一下dlbcl数据集吗,874176332@qq.com 谢谢
网址打不开
多刷新几次就打开了
还是不行,换了好几个浏览器也不行
刚刚看到消息,github被劫持了,等待一段时间即可恢复访问。
OK
您好,方便提供一下数据集吗?我也没找到。
1392350692@qq.com
数据集已上传至:https://github.com/xyjigsaw/Dataset
请问可以提供dlbcl数据集吗?谢谢,616837919@qq.com.
已发送
能否提供一下dlbcl数据集,网上没找到,还请博主发一下sghhrzq@163.com。谢谢了
博主,您好,您用过互信息来将特征分为几个组吗
另外,能否提供一下dlbcl数据集,网上没找到,还请博主发一下1159668795@qq.com。谢谢了
已发
找相关论文
数据集10折划分函数中Indices是单独设的吗
那个函数自动的不用管它
谢谢了 我还有一个问题 就是在muteinf这个函数中,最后两句代码,info = sum(sum(p .* log(p ./ (pA .* pY))));
info = 2 * info ./ (HA + HY);%计算互信息,前一个已经计算出来了两个向量的互信息了,最后一句是什么意思啊
博主您好 如果想实验自己的数据集 应该怎么改呀 我的数据集是.mat格式。小白一只还请解答~^^
请看我的最新文章:http://www.omegaxyz.com/2019/06/26/divide-dataset/
为什么divide那个函数用不了
这是我自己写的划分数据集的函数,输出是测试集,训练集,测试集标签和训练集标签。
划分数据集的函数能给我发一下吗
请看我的最新文章:http://www.omegaxyz.com/2019/06/26/divide-dataset/
您好,方便提供下dlbcl数据集吗?
您好,方便提供下dlbcl数据集吗
您好,没能在uci上找到dlbcl数据集,能麻烦您提供一下网址吗,非常感谢
请提供邮箱地址
dlbcl 数据集没找到,能发一份吗?谢谢