文章目录
文章转载自极客学院:http://wiki.jikexueyuan.com/project/tensorflow-zh/get_started/basic_usage.html
TensorFlow简介
TensorFlow 是 Google 开发的一款神经网络的 Python 外部的结构包,也是一个采用 数据流图 来进行数值计算的开源软件库。它被用于语音识别或图像识别等多项机器深度学习领域,它可在小到一部智能手机、大到数千台数据中心服务器的各种设备上运行。
为什么学习TensorFlow?
TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。
TensorFlow 无可厚非地能被认定为神经网络中最好用的库之一,它擅长的任务就是训练深度神经网络。通过使用 TensorFlow 我们就可以快速的入门神经网络,大大降低深度学习(也就是深度神经网络)的开发成本和开发难度;TensorFlow 的开源性让所有人都能使用并且维护、 巩固它,使它能迅速更新, 发展。
虽然可能有些人说 caffe 更适合图像,mxnet 效率更高等等,但其实这些框架一通百通,唯独语法不同而已,所以我们不必在此纠结过多。那么让我们从tensorflow开始吧。
Tensorflow 处理结构
TensorFlow 让我们可以先绘制计算结构图,也可以称是一系列可人机交互的计算操作, 然后把编辑好的Python文件转换成更高效的 C++,并在后端进行计算。
TensorFlow 首先要定义神经网络的结构,然后再把数据放入结构当中去运算和training
下面动图展示了 TensorFlow 数据处理流程:
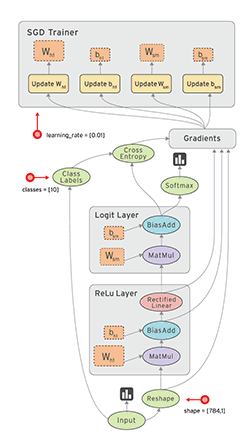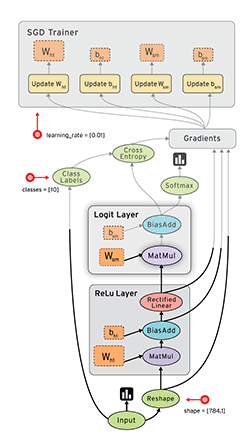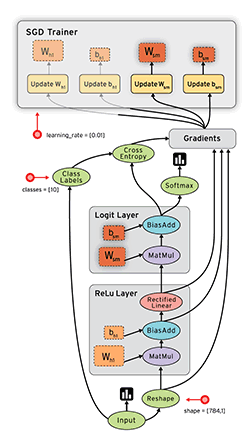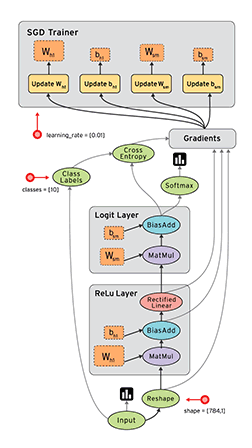
因为TensorFlow是采用 数据流图(data flow graphs)来计算, 所以首先我们得创建一个数据流图,然后再将我们的数据(数据以 张量(tensor) 的形式存在)放到数据流图中计算。
图中的 节点(Nodes)一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点/输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点;线(edges)则表示在节点间相互联系的多维数据数组,即 张量(tensor),训练模型时,tensor 会不断的从数据流图中的一个节点 flow 到另一节点, 这就是 TensorFlow 名字的由来。一旦输入端的所有张量准备好,节点将被分配到各种计算设备完成异步并行地执行运算。
它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。
Tensorflow 基本使用
使用TensorFlow,你必须明白TensorFlow:
- 使用图
(graph)来表示任务 - 被称之为会话
(Session)的上下文(context)中执行图 - 使用
tensor表示数据 - 通过变量
(Variable)维护状态 - 使用
feed和fetch可以为任意操作(arbitrary operation)赋值或者从其中获取数据
综述
TensorFlow是一个编程系统,使用图来表示计算任务,图中的节点被称之为op(operation的缩写),一个op获得0个或者多个tensor,执行计算,产生0个或多个tensor。每个tensor是一个类型化的多维数组。例如,你可以将一组图像素集表示为一个四维浮点数数组,这四个维度分别是[batch, height, width, channels]。
一个TensorFlow图描述了计算的过程,为了进行计算,图必须在会话里被启动,会话将图的op分发到诸如CPU或GPU之类的设备上,同时提供执行op的方法,这些方法执行后,将产生的tensor返回。在python语言中,返回的tensor是numpy ndarry对象;在C/C++语言中,返回的是tensor是tensorflow::Tensor实例。
计算图
Tensorflow程序通常被组织成一个构建阶段和一个执行阶段,在构建阶段,op的执行步骤被描述成为一个图,在执行阶段,使用会话执行图中的op。
例如,通常在构建阶段创建一个图来表示和训练神经网络,然后在执行阶段反复执行图中的训练op。
Tensorflow支持C/C++,python编程语言。目前,TensorFlow的python库更易使用,它提供了大量的辅助函数来简化构建图的工作,这些函数尚未被C/C++库支持。
三种语言的会话库(session libraries)是一致的。
构建图
构件图的第一步是创建源op (source op)。源op不需要任何输入。源op的输出被传递给其它op做运算。
python库中,op构造器的返回值代表被构造出的op输出,这些返回值可以传递给其它op作为输入。
TensorFlow Python库中有一个默认图(default graph),op构造器可以为其增加节点。这个默认图对许多程序来说已经足够用了,可以阅读Graph类文档,来了解如何管理多个视图。
默认图现在有三个节点,两个constant() op和matmul() op。为了真正进行矩阵乘法的结果,你必须在会话里启动这个图。
在一个会话中启动图
构造阶段完成后,才能启动图。启动图的第一步是创建一个Session对象,如果无任何创建参数,会话构造器将无法启动默认图。
欲了解完整的会话API,请阅读Session类。
Session对象在使用完成后需要关闭以释放资源,除了显式调用close外,也可以使用with代码来自动完成关闭动作:
在实现上,Tensorflow将图形定义转换成分布式执行的操作,以充分利用可以利用的计算资源(如CPU或GPU)。一般你不需要显式指定使用CPU还是GPU,Tensorflow能自动检测。如果检测到GPU,Tensorflow会尽可能地使用找到的第一个GPU来执行操作。
如果机器上有超过一个可用的GPU,除了第一个外的其他GPU是不参与计算的。为了让Tensorflow使用这些GPU,你必须将op明确地指派给它们执行。with...Device语句用来指派特定的CPU或GPU操作:
设备用字符串进行标识,目前支持的设备包括:
/cpu:0:机器的CPU/gpu:0:机器的第一个GPU,如果有的话/gpu:1:机器的的第二个GPU,以此类推
交互式使用
文档中的python示例使用一个会话Session来启动图,并调用Session.run()方法执行操作。
为了便于使用诸如IPython之类的python交互环境,可以使用InteractiveSession代替Session类,使用Tensor.eval()和Operation.run()方法代替Session.run()。这样可以避免使用一个变量来持有会话:
Tensor
Tensorflow程序使用tensor数据结构来代表所有的数据,计算图中,操作间传递数据都是tensor。你可以把Tensorflow的tensor看做是一个n维的数组或列表。一个tensor包含一个静态类型rank和一个shape。
阶
在Tensorflow系统中,张量的维数被描述为阶。但是张量的阶和矩阵的阶并不是同一个概念。张量的阶是张量维数的一个数量描述,下面的张量(使用python中list定义的)就是2阶:
你可以认为一个二阶张量就是我们平常所说的矩阵,一阶张量可以认为是一个向量。对于一个二阶张量,你可以使用语句t[i, j]来访问其中的任何元素。而对于三阶张量你可以通过t[i, j, k]来访问任何元素:
| 阶 | 数学实例 | python例子 |
|---|---|---|
0 |
纯量(只有大小) | s=483 |
1 |
向量(大小和方向) | v=[1.1, 2.2, 3.3] |
2 |
矩阵(数据表) | m=[[1, 2, 3], [4, 5, 6], [7, 8, 9]] |
3 |
3阶张量 |
t=[[[2], [4], [6]], [[8], [9], [10]], [[11], [12], [13]]] |
n |
n阶 |
…… |
形状
Tensorflow文档中使用了三种记号来方便地描述张量的维度:阶,形状以及维数。以下展示了它们之间的关系:
| 阶 | 形状 | 维数 | 实例 |
|---|---|---|---|
0 |
[] |
0-D | 一个0维张量,一个纯量 |
1 |
[D0] |
1-D | 一个1维张量的形式[5] |
2 |
[D0, D1] |
2-D | 一个2维张量的形式[3, 4] |
3 |
[D0, D1, D2] |
3-D | 一个3维张量的形式[1, 4, 3] |
n |
[D0, D1, ... Dn] |
n-D | 一个n维张量的形式[D0, D1, ..., Dn] |
数据类型
除了维度,tensor有一个数据类型属性。你可以为一个张量指定下列数据类型中的任意一个类型:
| 数据类型 | python类型 | 描述 |
|---|---|---|
DT_FLOAT |
tf.float32 |
32位浮点数 |
DT_DOUBLE |
tf.float64 |
64位浮点数 |
DT_INT64 |
tf.int64 |
64位有符号整型 |
DT_INT32 |
tf.int32 |
32位有符号整型 |
DF_INT16 |
tf.int16 |
16位有符号整型 |
DT_INT8 |
tf.int8 |
8位有符号整型 |
DT_UINT8 |
tf.uint8 |
8位无符号整型 |
DT_STRING |
tf.string |
可变长度的字节数组,每一个张量元素都是一个字节数组 |
DT_BOOL |
tf.bool |
布尔型 |
DT_COMPLEX64 |
tf.complex64 |
由32位浮点数组成的负数:实数和虚数 |
DT_QINT32 |
tf.qint32 |
用于量化Ops的32位有符号整型 |
DT_QINT8 |
tf.qint8 |
用于量化Ops的8位有符号整型 |
DT_QUINT8 |
tf.quint8 |
用于量化Ops的8位无符号整型 |
变量
在Variables 中查看更多细节。变量维护图执行过程中的状态信息。下面的例子演示了如何使用变量实现一个简单的计数器:
代码中assign()操作是图所描述的表达式的一部分,正如add()操作一样,所以在调用run()执行表达式之前,它并不会真正执行赋值操作。
通常会将一个统计模型中的参数表示为一组变量。例如,你可以将一个神经网络的权重作为某个变量存储在一个tensor中。在训练过程中,通过反复训练图,更新这个tensor。
Fetch
为了取回操作的输出内容,可以在使用Session对象的run()调用执行图时,传入一些tensor,这些tensor会帮助你取回结果。在之前的例子里,我们只取回了单个节点state,但是你也可以取回多个tensor:
需要获得更多个tensor值,在op的依次运行中获得(而不是逐个去获得tenter)。
Feed
上述示例在计算图中引入tensor,以常量或变量的形式存储。Tensorflow还提供了feed机制,该机制可以临时替代图中的任意操作中的tensor可以对图中任何操作提交补丁,直接插入一个tensor。
feed使用一个tensor值临时替换一个操作的输出结果,你可以提供feed数据作为run()调用的参数。feed只在调用它的方法内有效,方法结束,feed就会消失。最常见的用例是将某些特殊的操作指定为feed操作,标记的方法是使用tf.placeholder()为这些操作创建占位符。
参考链接
文章转载自极客学院:http://wiki.jikexueyuan.com/project/tensorflow-zh/get_started/basic_usage.html