文章目录
In-KG应用(在 KG 范围内的应用)
链接预测(Link prediction)
链接预测任务有时也称为实体预测或实体排序,用来预测两个实体之间是否有特定的关系。即已知头实体h和关系r,预测尾实体t;或者尾实体t和关系r,预测头实体h。它的本质是一个KG补全的任务,即将缺失的知识添加到图谱中。同时也可以预测两个给定实体之间的关系,即已知头尾实体,求r。
以预测头实体为例,可以将 KG 中每个实体 h 作为候选答案,然后为每个实体计算 f(h,t) 分数。为了进行评估,通常的做法是将正确答案的排列顺序记录在有序列表中,以便查看是否可以将正确答案排列在错误答案之前。正确答案排序数越小表示性能越好。基于这些排序设计了各种评价标准,如平均排序 (预测的排序数字的平均值)、平均倒数排序 (倒数排序的平均值)、Hits@n(n 个正确排序所占的比例)、AUC-PR(准确率 - 召回率曲线下的面积)。
三元组分类(Triple Classification)
三元组分类用来判断三元组表示的事实(h,r,t)真假,同样这个任务可以看做一个KG输入补全。为评分函数设置一个阈值,以阈值来判断该事实是否是正确的。
实体分类(Entity Classification)
实体分类可以看作是一个具体的链接预测任务,目的是将实体划分为不同的语义类别。类似的预测和评估方法和链接预测相同。
实体解析(Entity Resolution)
判断两个实体是否指的是同一个对象。例如北大和北京大学两个实体实际上是同一个对象。实体解析可以删除这些重复的节点。若关系声明两个实体是否相等 (表示为 EqualTo),并且已经学习了该关系的嵌入。在这种情况下,实体解析退化为三元组分类问题,即, 判断三元组(x,EqualTo,y)是否正确。
Out-of-KG应用(突破 KG 输入边界并扩展到更广泛领域的应用)
关系提取(Relation Extraction)
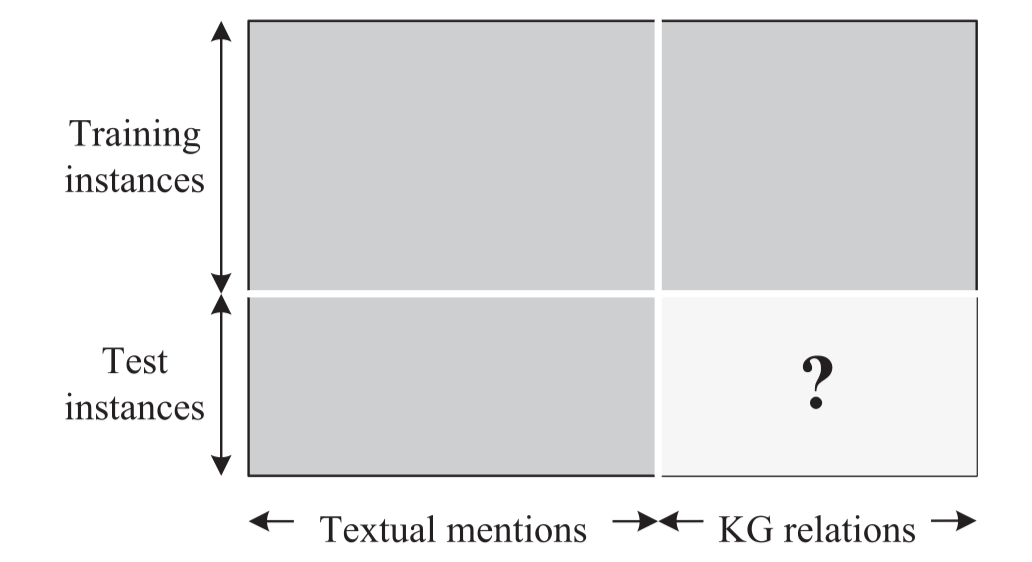
目的是从已经检测到实体的纯文本中抽取关系事实。目前有TransE与基于文本的抽取器相结合的方法进行关系抽取。另外还可以将纯文本和KG关系联合嵌入,即文本和 KGs 被表示在同一个矩阵中。矩阵的每一行代表一对实体,每一列代表一个提及的文本或 KG 关系,如果两个实体与纯文本中的一个提到或与 KGs 中的关系同时出现,则将相应的条目设置为 1,否则设置为 0。从图中可以看到训练实例可以同时看到文本提及和KG关系,但在测试实例中,只包含文本提及。因此,关系提取用于预测测试实例缺少的 KG 关系。
问答系统(Question Answering)
给定一个用自然语言表达的问题,任务是从KG中检索由三元组或三元组支持的正确答案。一个可行的方法是学习单词和 KG 成分的低维向量嵌入,使问题的表示和相应的答案在嵌入空间中相互接近。
推荐系统(Recommender Systems)
推荐系统的应用很广泛,一种方法是将用户与商品之间的交互建模为用户与商品之间的即时表示的产品的协同过滤技术,但是用户与商品之间的交互可能很稀疏。有学者提出了一种混合推荐框架,该框架利用 KG 内的异构信息来提高协同过滤的质量——使用存储在 KG 的三种类型的信息, 包括结构性知识 (事实三元组), 文本知识 (例如, 一本书或一部电影的文本性的总结), 和视觉知识 (例如, 一本书的封面或电影海报图片), 为每项生成语义表示。