

数据集,又称为资料集、数据集合或资料集合,是一种由数据所组成的集合。Data set(或dataset)是一个数据的集合,通常以表格形式出现。每一列代表一个特定变量。每一行都对应于某一成员的数据集的问题。它列出的价值观为每一个变量,如身高和体重的一个物体或价值的随机数。每个数值被称为数据资料。对应于行数,该数据集的数据可能包括一个或多个成员。
——百度百科
下面是个人的理解
![]() 数据集名称GLIOMA
数据集名称GLIOMA
GIOMA包含两个矩阵,一个是实例矩阵(ins),另一个是标签矩阵(lab)
![]()
Ins矩阵大小50*4434,说明该GLIOMA数据集有50个实例(样本),有4434个特征,这50个实例(样本),每一个实例有一个对应的标签lab,标签就是类别。
打开Ins矩阵,有50行说明有50个实例(样本),有4434列说明有4434个特征(太多了显示不了),这里面的任意一个值(标量)叫做特征值,任意一列是特征向量(列向量),任意一行是实例向量(行向量)
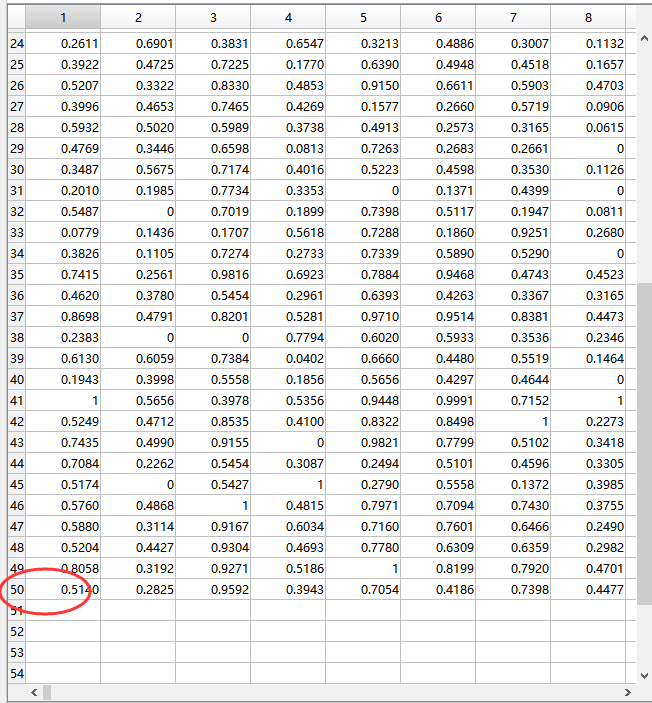
打开lab矩阵
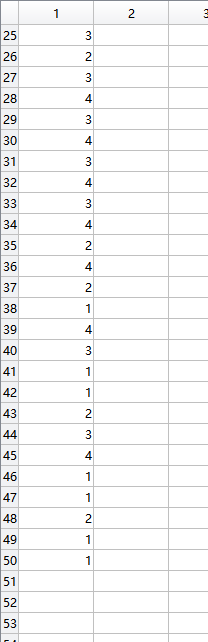
有50个标签,标签就是类别(比如1代表幼儿,2代表青年,以此类推),可以看到这是一个具有4个类别的数据集。
另外不要把实例与个体混淆,实例单指数据集中(原空间),实例的个数一般是不变的。个体是作为演化计算算法中的种群来说的,可以根据自己的喜好设置个体数量。比如PSO算法中的个体就是粒子。实例与个体有一点相似就是特征数(维度)相同。
数据集的下载(从UCI下载):
http://archive.ics.uci.edu/ml/index.php
当然下载的数据集可能标签和特征是放在一起的可以自己分开

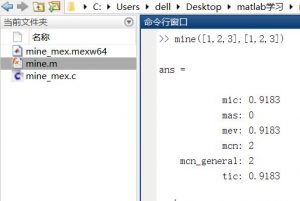
那能够正确分类的实例数和参与分类的实例数是什么意思博主知道吗
前面就是样本预测正确,后面的指所有样本。
谢谢分享,不忘初心!