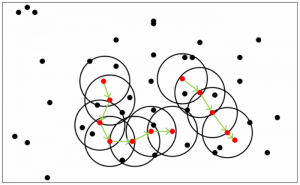
度量相似性(similarity measure)即距离度量,在生活中我们说差别小则相似,对应到多维样本,每个样本可以对应于高维空间中的一个数据点,若它们的距离相近,我们便可以称它们相似。
距离度量的基本性质
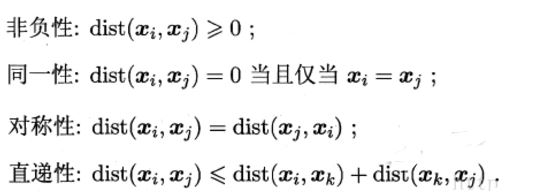
注意最后一个可以理解为三角形两边之和大于第三边。
欧式距离
欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
对应于机器学习即对应属性之间相减的平方和再开根号。
闵可夫斯基距离(Minkowski distance)
曼哈顿距离(Manhattan distance)
切比雪夫距离(Chebyshev distance)
闵可夫斯基距离是度量在赋范向量空间,其可以被认为是两个的一般化欧几里德距离和曼哈顿距离。
两点之间的闵可夫斯基距离
![]()
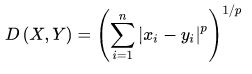
当p=1时,闵可夫斯基距离即曼哈顿距离(Manhattan distance):
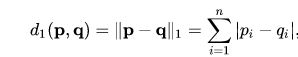
当p=2时,闵可夫斯基距离即欧氏距离(Euclidean distance)
在p达到无穷大的极限情况下,我们得到切比雪夫距离(Chebyshev distance)
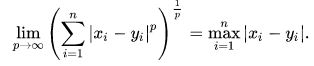
闵可夫斯基距离也可以看作P和Q之间分量差异的平均值的倍数。
下图显示了具有各种p值的单位圆:

我们知道属性分为两种:连续属性和离散属性(有限个取值)。对于连续值的属性,一般都可以被学习器所用,有时会根据具体的情形作相应的预处理,例如:归一化等;而对于离散值的属性,需要作下面进一步的处理:
若属性值之间存在序关系,则可以将其转化为连续值,例如:身高属性“高”“中等”“矮”,可转化为{1, 0.5, 0}。
若属性值之间不存在序关系,则通常将其转化为向量的形式,例如:性别属性“男”“女”,可转化为{(1,0),(0,1)}。
在进行距离度量时,易知连续属性和存在序关系的离散属性都可以直接参与计算,因为它们都可以反映一种程度,我们称其为“有序属性”;而对于不存在序关系的离散属性,我们称其为:“无序属性”,显然无序属性再使用闵可夫斯基距离就行不通了。
对于无序属性,我们一般采用VDM进行距离的计算,例如:对于离散属性的两个取值a和b,定义(p200):
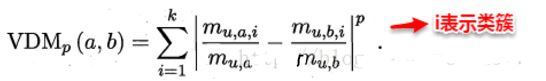
是,在计算两个样本之间的距离时,我们可以将闵可夫斯基距离和VDM混合在一起进行计算:
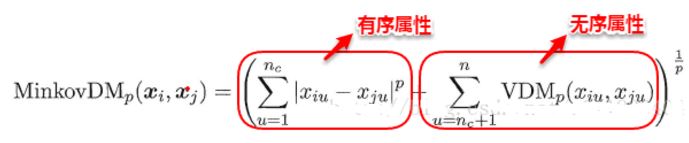
若我们定义的距离计算方法是用来度量相似性,例如下面将要讨论的聚类问题,即距离越小,相似性越大,反之距离越大,相似性越小。这时距离的度量方法并不一定需要满足前面所说的四个基本性质,这样的方法称为:非度量距离(non-metric distance)。