

网页版微博是纯正的HTML,而且调用的微博自家的API来获取图片。
网址:https://m.weibo.cn/api/container/即为微博api里面包含了个人的信息与微博文字与图片存储地址。

进入api页面我们可以很清晰的看到各种信息都用json存储起来了。我们再利用python中的json库提取出来即可。这比其它利用cookie模拟登陆要方便很多,我们只要输入被爬虫用户的微博ID然后运行便能自动爬取。
ID从这个复制链接里面可以看出来。
代码采用Python3
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
# -*- coding: utf-8 -*- import urllib.request import json import requests import os path = 'C:\\Users\\dell\\Desktop\\weibo\\' id = '2093492691' proxy_addr = "122.241.72.191:808" pic_num = 0 weibo_name = "programmer" def use_proxy(url,proxy_addr): req=urllib.request.Request(url) req.add_header("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0") proxy=urllib.request.ProxyHandler({'http':proxy_addr}) opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler) urllib.request.install_opener(opener) data=urllib.request.urlopen(req).read().decode('utf-8','ignore') return data def get_containerid(url): data=use_proxy(url,proxy_addr) content=json.loads(data).get('data') for data in content.get('tabsInfo').get('tabs'): if(data.get('tab_type')=='weibo'): containerid=data.get('containerid') return containerid def get_userInfo(id): url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id data=use_proxy(url,proxy_addr) content=json.loads(data).get('data') profile_image_url=content.get('userInfo').get('profile_image_url') description=content.get('userInfo').get('description') profile_url=content.get('userInfo').get('profile_url') verified=content.get('userInfo').get('verified') guanzhu=content.get('userInfo').get('follow_count') name=content.get('userInfo').get('screen_name') fensi=content.get('userInfo').get('followers_count') gender=content.get('userInfo').get('gender') urank=content.get('userInfo').get('urank') print("微博昵称:"+name+"\n"+"微博主页地址:"+profile_url+"\n"+"微博头像地址:"+profile_image_url+"\n"+"是否认证:"+str(verified)+"\n"+"微博说明:"+description+"\n"+"关注人数:"+str(guanzhu)+"\n"+"粉丝数:"+str(fensi)+"\n"+"性别:"+gender+"\n"+"微博等级:"+str(urank)+"\n") def get_weibo(id,file): global pic_num i=1 while True: url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id weibo_url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id+'&containerid='+get_containerid(url)+'&page='+str(i) try: data=use_proxy(weibo_url,proxy_addr) content=json.loads(data).get('data') cards=content.get('cards') if(len(cards)>0): for j in range(len(cards)): print("-----正在爬取第"+str(i)+"页,第"+str(j)+"条微博------") card_type=cards[j].get('card_type') if(card_type==9): mblog=cards[j].get('mblog') attitudes_count=mblog.get('attitudes_count') comments_count=mblog.get('comments_count') created_at=mblog.get('created_at') reposts_count=mblog.get('reposts_count') scheme=cards[j].get('scheme') text=mblog.get('text') if mblog.get('pics') != None: # print(mblog.get('original_pic')) # print(mblog.get('pics')) pic_archive = mblog.get('pics') for _ in range(len(pic_archive)): pic_num += 1 print(pic_archive[_]['large']['url']) imgurl = pic_archive[_]['large']['url'] img = requests.get(imgurl) f = open(path+weibo_name+'\\'+str(pic_num)+ str(imgurl[-4:]), 'ab') # 存储图片,多媒体文件需要参数b(二进制文件) f.write(img.content) # 多媒体存储content f.close() with open(file,'a',encoding='utf-8') as fh: fh.write("----第"+str(i)+"页,第"+str(j)+"条微博----"+"\n") fh.write("微博地址:"+str(scheme)+"\n"+"发布时间:"+str(created_at)+"\n"+"微博内容:"+text+"\n"+"点赞数:"+str(attitudes_count)+"\n"+"评论数:"+str(comments_count)+"\n"+"转发数:"+str(reposts_count)+"\n") i+=1 else: break except Exception as e: print(e) pass if __name__ == "__main__": if os.path.isdir(path+weibo_name): pass else: os.mkdir(path+weibo_name) file = path+weibo_name+'\\'+weibo_name+".txt" get_userInfo(id) get_weibo(id, file) |
最终的效果图(爬取的微博txt文件):

爬取的微博图片:
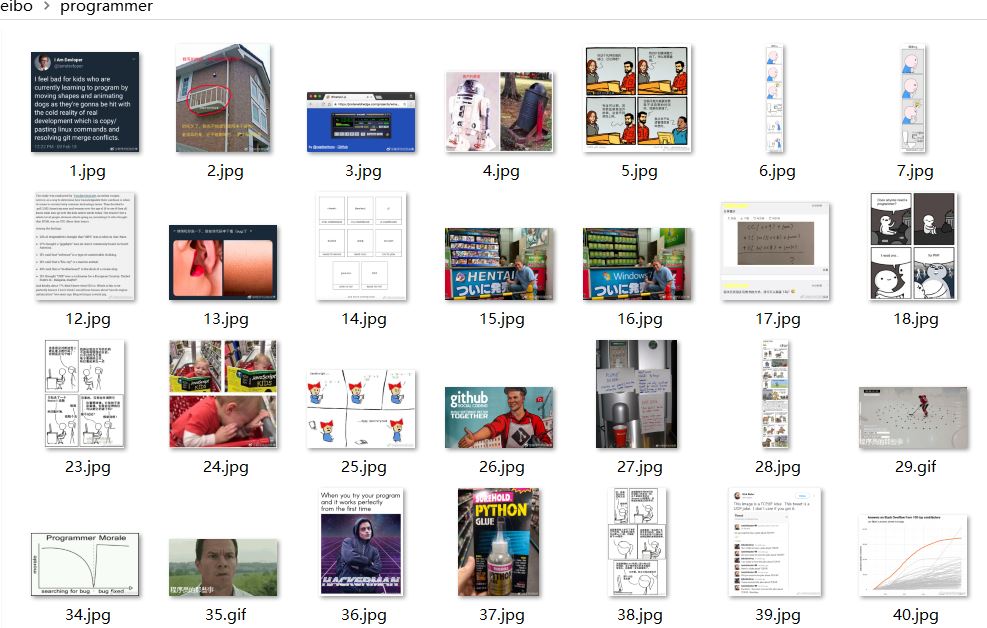
以后下壁纸就很简单啦!!!
GUI程序:http://www.omegaxyz.com/2018/02/14/python_weibo_gui/




大佬 为什么运行源代码只能爬到一百八十多页?其他人有这样的问题吗?
年代久远,这个代码现在还能跑嘛?
欢迎您push最新的代码到:https://github.com/xyjigsaw/Weibo-Crawler-GUI
能跑,但是很奇怪的跑到将近200页的时候输出的cards就会变成空值,但是将网站直接贴到浏览器上面又显示明明是有json值的
可能是微博的反爬机制,欢迎你调试并push最新的代码到https://github.com/xyjigsaw/Weibo-Crawler-GUI
还可以 但是只能前50页了,之后无限循环
欢迎帮忙修改一下代码:https://github.com/xyjigsaw/Weibo-Crawler-GUI
请问怎么保存为.csv?
使用csv库即可。
您好 可否选择时间范围进行爬取?请问可以怎么修改?
应该是可以的,只需要捕获到发表时间即可。
你好老師, 我是個初學者, 請問如果我想把下載的相片根據相片的發布日期命名排序, 我應該如何修改代碼?
另外如果想同時下載視頻, 是不是難以實踐, 感謝
你好,你可以把他们的meta信息放到同一个tuple里面,然后排序。
Nice!
I copied the code!
我像个憨批,我ID拿错了
[…] 前两天在网上偶然看到一个大佬OmegaXYZ写的文章,Python爬取微博文字与图片(不使用Cookie) […]
找到了用户id,但是脚本函数get_userInfo返回{“ok”:0,”msg”:”\u8fd9\u91cc\u8fd8\u6ca1\u6709\u5185\u5bb9″,”data”:{“cards”:[]}}。但是使用浏览器打开却是正常的{“ok”:1…………(省略)。修改了User-Agent,也没好。请指导!
抱歉,细节我记不大清楚了
谢谢回复。再请教一下https://m.weibo.cn/api/container/getIndex?type=uid&value=这个微博的API是怎么得到的?我查看了检查选项没找到,难道要抓包吗?谢谢
已解决
GUI 源码:https://github.com/xyjigsaw/Weibo-Crawler-GUI
请问您的问题解决了吗?我现在也遇到了同样的问题
你好,这个container和直接查看网页源码获取到的图片链接一样吗?有时间请楼主解答
这个是用户发的原图
长见识了
[…] 前两天在网上偶然看到一个大佬OmegaXYZ写的文章,Python爬取微博文字与图片(不使用Cookie) […]
博主的方法是把客户端伪装成了浏览器,设置proxy和user agent,但是这样浏览器端必须登陆过微博才可以用,我理解的对吗?
如果我想在一个app里面模拟,也要做这些操作了?
麻烦作者回复一下,谢谢
不是这样的,这个我是直接调用微博的api,我设置proxy和useragent是为了反反爬虫,不需要登录微博,如果你想在app里面模拟,直接调用代码中的url的api即可。
🐂🍺,楼主这个方法厉害了。我准备写一个C#版本,学习了,谢谢了
Nice