3型文法(正则文法,线性文法)
如果对于某文法G,P中的每个规则具有下列形式:
U :: = T 或 U :: = WT
其中T∈VT;U,W∈VN,则称该文法G为左线性文法。
如果对于某文法G,P中的每个规则具有下列形式:
U :: = T 或 U :: = TW
其中T∈VT;U, W∈VN,则称该文法G为右线性文法。
左线性文法和右线性文法通称为3型文法或正则文法,有时又称为有穷状态文法,简写为RG。
按照定义,对于正则文法应用规则时,单个非终结符号只能被替换为单个终结符号,或被替换为单个非终结符号加上单个终结符号,或者被替换为单个终结符号加上单个非终结符号。
3型文法所确定的语言为3型语言L3,3型语言可由确定的有限状态自动机来识别。
程序设计语言的单词可由正则文法产生,例如,标识符的定义可由正则文法描述如下:
<标识符>::=<字母>/<标识符><字母>/<标识符><数字>
显然,该文法描述了以字母开头的字母数字串的集合。现在要引入另一种适合于描述单词的表示法——正则表达式。正则表达式又称为正则式,每个正则表达式描述的集合称为正则集。
之所以采用正则表达式来描述,主要基于以下几点原因:
- 词法规则简单,无需上下文无关文法那样严格的表示法,用正则式表示法来理解被定义的符号集合比理解由重写规则集合定义的语言更为容易;
- 从正则式构造高效识别程序比上下文无关文法更容易;
- 可以从某个正则式自动地构造识别程序,它可以识别用该正则式表示的字符串集合中的字符串,从而减轻后面要介绍的词法分析时的工作量。
- 可用于其他各种信息流的处理,例如,已经应用于某些模式识别问题、文献目录检索系统以及正文编辑程序等。
正则表达式和正则集
设有字母表∑。∑上的正则表达式和它所表示的正则集递归地定义如下:
- ε和Φ都是∑上的正则表达式,它们所表示的正则集分别为{ε}和Φ,其中ε是空串,Φ是空集;
- 任意的a∈∑是正则表达式,它所表示的正则集是{a};
- 如果e1和e2是∑上的任意的正则表达式,且分别表示的正则集为L(e1)和L(e2),则:
- e1/e2也是正则表达式,表示的正则集为L(e1 / e2)=L(e1)∪L(e2)。
- e1 e2也是正则表达式,表示的正则集为L(e1 e2)=L(e1)L(e2)。
- (e1)*也是正则表达式,表示的正则集为L((e1)*)=L(e1)*。
定义中(1)和(2)定义了原子正则表达式,而(3)则表明字母表∑上的正则表达式可由原子正则表达式或较简单的正则表达式通过联合、连接与闭包运算构成一般的正则表达式。
正则表达式的性质
如果两个正则表达式e1和e2表示的正则集相同,即值相等,则称它们是等价的。记为e1=e2。
正则表达式与正则文法的关系
一个正则表达式的值是正则集,它是正则语言的另一种表示法。不难看出,除了符号Φ外,一个正则表达式的含义类似于正则文法的一个非终结符号规则右部的含义。例如,对于<数字> ::= 0/1/2/…/9,由非终结符数字所产生的字符串集合与正则表达式0/1/2/…/9所定义的字符串集合是相同的。正则集Φ,它对应一个不包含任何句子的语言,引进的目的主要是为了理论上的完备性。
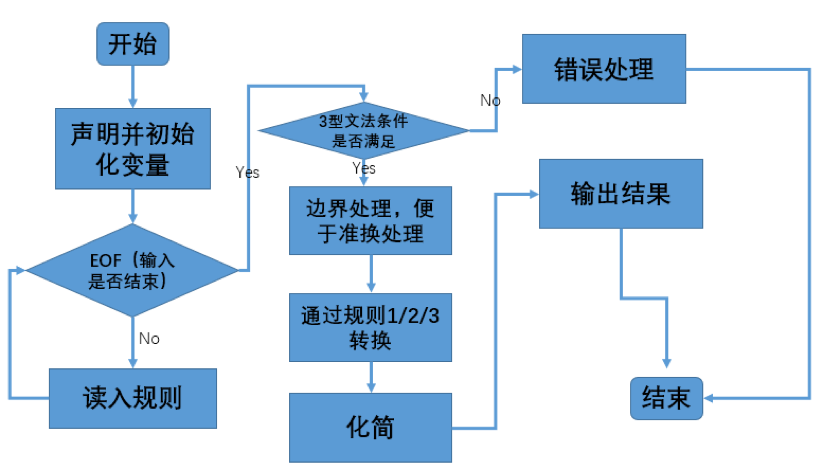
流程图
代码
规则的数据结构:包含两个string对象,一个是left即文法的产生式左边部分,另一个是right即文法产生式的右半部分。
|
1 2 3 4 |
struct Principle{ string left; string right; }; |
文法的数据结构:考虑到文法是一个四元组,包含Vn为非终结符,Vt为终结符,P为文法的规则,S为识别符或开始符,flag为文法的类型,因此下面使用C++中的类来为文法定义,并且使用set集合来保存每个文法的某些属性(不会重复)。
|
1 2 3 4 5 6 7 8 |
class Grammar{ public: set<char> Vn; set<char> Vt; set<Principle> P; char S; int flag = -1; }; |
ALL:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 |
// // main.cpp // demo // // Created by 徐奕 on 2018/11/2. // Copyright © 2018 Reacubeth. All rights reserved. // #include<cstdio> #include<iostream> #include<string> #include<vector> #include<set> #define MAX_LENGTH 10 using namespace std; struct Principle{ string left; string right; }; struct Grammar{ set<char> Vn; set<char> Vt; vector<Principle> P; set<Principle> R; char S; int flag = -1; }; void input(vector<Principle> &principleSet,int time) { char tempLeft[MAX_LENGTH]; char tempRight[MAX_LENGTH]; int temp2=0; while(scanf("%[^-]->%s",tempLeft,tempRight)!=EOF){ getchar(); Principle temp; temp.left = tempLeft; temp.right = tempRight; principleSet.push_back(temp); temp2++; if(temp2==time)break; } } void analyseGram(Grammar &G) { G.S = G.P.front().left[0]; for(int i=0;i<G.P.size();++i){ Principle &temp = G.P[i]; for(int j = 0;j<temp.left.size();++j){ char v = temp.left[j]; if(!isupper(v)){ G.Vt.insert(v); }else{ G.Vn.insert(v); } } for(int j = 0;j<temp.right.size();++j){ char v = temp.right[j]; if(!isupper(v)){ G.Vt.insert(v); }else{ G.Vn.insert(v); } } } } bool existVNT(string s) { for(int i=0;i<s.size();i++){ if(isupper(s[i])){ return true; } } return false; } void judgeGram(Grammar &G) { for(int i=0;i<G.P.size();++i){ if(existVNT(G.P[i].left)){ G.flag = 0; break; } } int temp = 0; for(int i=0;i<G.P.size()&&G.flag==0;++i){ if(G.P[i].left.size()<=G.P[i].right.size()){ temp++; } } if(temp==G.P.size()){ G.flag=1; } temp = 0; for(int i=0;i<G.P.size()&&G.flag==1;++i){ if(1==G.P[i].left.size()&&isupper(G.P[i].left[0])){ temp++; } } if(temp==G.P.size()){ G.flag=2; } temp = 0; for(int i=0;i<G.P.size()&&G.flag==2;++i){ if(1==G.P[i].left.size()&&isupper(G.P[i].left[0])&& (1==G.P[i].right.size()&&!isupper(G.P[i].right[0])||2==G.P[i].right.size()&&!isupper(G.P[i].right[0])&& isupper(G.P[i].right[G.P[i].right.size()-1]))){temp++;} } if(temp==G.P.size()){ G.flag=3; } } void printResult(Grammar &G) { cout<<"G=(Vn,Vt,P,S):"<<G.flag<<"型文法"<<endl<<endl; cout<<"非终结符Vn:"; for(set<char>::iterator i = G.Vn.begin();i!=G.Vn.end();++i){ cout<<*i<<" "; } cout<<endl; cout<<"终结符Vt:"; for(set<char>::iterator i = G.Vt.begin();i!=G.Vt.end();++i){ cout<<*i<<" "; } cout<<endl; cout<<"起始符为:"<<G.S<<endl; cout<<"规则P如输入所示"<<endl; cout<<endl; } void clearP(Principle &P){ P.left=""; P.right=""; } void transfer2R(Grammar &G){ int i,j; for(int i=0;i<G.P.size();i++){ for(int j=i+1;j<G.P.size();j++){ if(G.P[i].left == G.P[j].left && G.P[i].right[1]==G.P[j].right[1]&&G.P[i].right.length()>1){ //cout<<"xxxx"<<endl; G.P[i].right=G.P[i].right+"|"+G.P[j].right; clearP(G.P[j]); } ///////////// //规则3 //cout<<"!"<<G.P[i].left<<G.P[i].right<<G.P[j].left<<G.P[j].right<<endl; if(G.P[i].right.length()==1&&G.P[j].right.length()==1&&G.P[i].left==G.P[j].left){ G.P[i].right = G.P[i].right+"|"+G.P[j].right; clearP(G.P[j]); //cout<<"!!"<<G.P[i].right<<endl; } } } int flag,m; for(int i=0;i<G.P.size();i++){// S->aA|bA 2 S->(a|b)A flag=G.P[i].right.length(); if(G.P[i].right.length()>2&&'A'<=G.P[i].right[1]&&G.P[i].right[1]<='Z'&&G.P[i].right[2]=='|'){ //cout<<"!"<<G.P[0].right<<endl; int j=0; for(j=1; j<flag-1;j=j+3){ G.P[i].right[j]=' '; } if(j == flag-1){ G.P[i].right="("+G.P[i].right.substr(0,G.P[i].right.length()-1)+")"+G.P[i].right.substr(G.P[i].right.length()-1); } } } //cout<<G.P[0].right<<endl; /* for(int i=0;i<G.P.size();i++){// S->aA|bA 2 S->(a|b)A flag=G.P[i].right.length(); int k=0,m,t=0; for(j=0;j<flag;j++){ for(k=j+1;k<flag;k++){ //cout<<G.P[i].right[j]<<G.P[i].right[k]<<endl; if(G.P[i].right[j]==G.P[i].right[k]&&G.P[i].right[j]>='A'&&G.P[i].right[j]<='Z'){t=1;break;} } if(t==1)break; } G.P[i].right[j]=' '; string temp = G.P[i].right; G.P[i].right="("; for(m=0;m<k;m++){ G.P[i].right=G.P[i].right+temp[m]; } G.P[i].right = G.P[i].right+")"; for(m=k;m<flag;m++){ G.P[i].right=G.P[i].right+temp[m]; } } */// for(int i=0;i<G.P.size();i++){ if(G.P[i].left[0]==G.P[i].right[G.P[i].right.length()-1]&&G.P[i].right.length()>1){ for(int j=0; j<G.P.size();j++){ if(G.P[i].left==G.P[j].left&&j!=i){ for(m=0;m<=G.P[j].right.length();m++){ if('A'<=G.P[j].right[m]&&G.P[j].right[m]<='Z'){ break;} if(m==G.P[j].right.length()){ G.P[i].right=G.P[i].right.substr(0,G.P[i].right.length()-1)+"*"+"("+G.P[j].right+")"; clearP(G.P[j]); } } } } } } for(int i=0;i<G.P.size();i++){ if(G.P[i].right.length()>1&&G.P[i].left[0]!=G.P[i].right[G.P[i].right.length()-1]){ for(int j=0;j<G.P.size();j++){ if(G.P[j].right.length()>1 && G.P[i].right[G.P[i].right.length()-1]==G.P[j].left[0]&&G.P[j].left[0]==G.P[j].right[G.P[j].right.length()-1]){ G.P[i].right=G.P[i].right.substr(0,G.P[i].right.length()-1)+G.P[j].right.substr(0,G.P[j].right.length()-1)+"*"+G.P[j].right[G.P[j].right.length()-1]; clearP(G.P[j]); } } } } flag = G.P.size(); for(int k=0;k<flag;k++){ for(int i=0;i<G.P.size();i++,flag--){ int j; //cout<<i<<" "<<flag<<endl; for(j=0;j<G.P[i].right.length();j++){ if('A'<=G.P[i].right[j]&&G.P[i].right[j]<='Z'){ for(m=0;m<G.P.size();m++){ if(G.P[m].left[0]==G.P[i].right[j]&&m!=i){ G.P[i].right=G.P[i].right.substr(0,j)+G.P[m].right+G.P[i].right.substr(j+1); clearP(G.P[m]); break; } } } } } } for(i=0;i<G.P.size();i++){ for(j=0;j<G.P.size();j++){ if(G.P[i].left[0]==G.P[j].left[0]&&i!=j){ if(G.P[j].right.length()>1){ G.P[i].right=G.P[i].right+"|"+"("+G.P[j].right+")"; clearP(G.P[j]); }else{ G.P[i].right=G.P[i].right+"|"+G.P[j].right; clearP(G.P[j]); } } } } } int main(){ Grammar G; G.Vn.clear(); G.Vt.clear(); int time; cout<<"input:"; cin>>time; getchar(); input(G.P,time); G.flag = 3; analyseGram(G); judgeGram(G); //printResult(G); transfer2R(G); //cout<<"正则表达式: "; for(int i=0;i<G.P.size();i++){ if(G.P[i].left.length()!=0){ cout<<G.P[i].left<<"="; for(int j=0;j<G.P[i].right.length();j++){ if(G.P[i].right[j]!=' ')cout<<G.P[i].right[j]; } cout<<endl; } } } |
测试用例
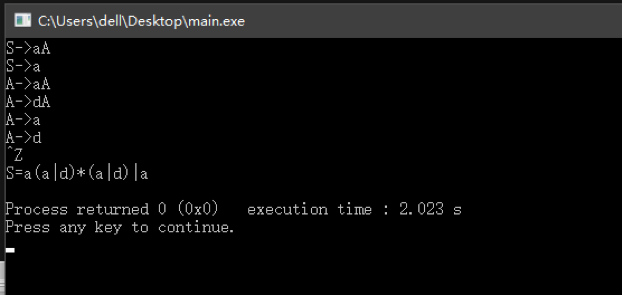
1:
S->aA
S->a
A->aA
A->dA
A->a
A->d
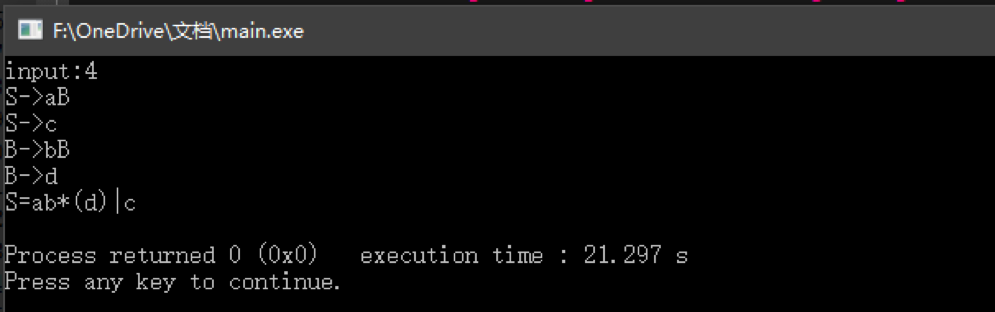
2:
S->aB
S->c
B->bB
B->d
遇到的困难与解决方法
①通常如果只有两个相同的非终结符的规则S->a,S->b那么可以直接化简为S->a|b,如果存在多个目标结果为S->a|b|c,那么,需要进行特殊处理,可以使用栈或者递归调用来生成多个或式。
②闭包*的识别,即规则2也是本次实验的难点,需要同时识别文法规则的左右两边。
③有时经过规则1、2和3后所得的结果仍然不正确,这就需要使用集成开发环境的调试工具。增强调试技巧也是非常重要的。
④最后阅读相关文献,发现将正规文法转为正规式可以用解联立方程组的思想进行实现,因此可以用MATLAB解符号函数的方法来写代码。