

NLF讲的是在不考虑具体问题的情况下,没有任何一个算法比另一个算法更优,甚至没有胡乱猜测更好。
- 不存在一个与具体应用无关的,普遍适用的“最优分类器”
- 学习算法必须要作出一个与问题领域有关的“假设”,分类器必须与问题域相适应。
但是,NFL定理的前提是,所有问题出现的机会相等、或所有问题都是同等重要。但是现实中,我们往往会得到特定的数据,特定的分布,解决特定的问题,所以我们只需要解决自己关注的问题,而不需要考虑这个模型是否很好的解决其他的问题。只有对于特定的问题,我们比较不同模型的才有意义。
不仅是机器学习,我们在做其他算法的时候也是这样,如果不考虑实际解决的问题,很难说算法的优劣。
比如:
d = 训练集合;
m = 训练集合中的元素个数;
f = 目标的输入输出关系;
h = 假设算法f的输入参数为d,结果为h
C =针对f,h的离线训练损失函数
如果以下面的参数来衡量,所有的算法都是相同的: E(C|d), E(C|m), E(C|f,d), or E(C|f,m).
结论:
我们比较两种算法A与B:
1. 对于所有的问题,A并不总是优于B
2. 对于所有的问题,特定算法并不总是比随机算法好。
如下图:
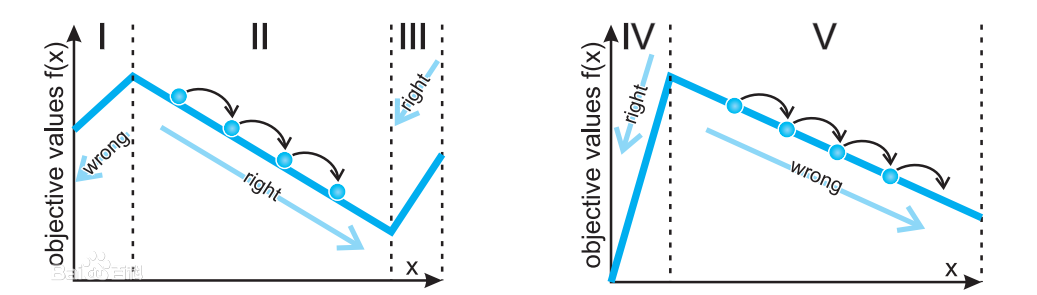
NFL定理最重要的寓意,是让我们清楚地认识到,脱离具体问题,空泛地谈论”什么学习算法更好“毫无意义,因为若考虑所有潜在的问题,则所有的算法一样好. 要谈论算法的相对优劣,必须要针对具体问题;在某些问题上表现好的学习算法,在另一问题上却可能不尽如人意,学习算法自身的归纳偏好与问题是否相配,往往会起到决定性作用。——周志华
参考资料:


