

DROP3算法
目的:保留类边界上的实例,去除类内部的实例,构造代理训练集
主要思想:利用KNN算法及排序来去除噪音实例
算法步骤
①先去除训练集上所有KNN算法错误分类的特征
②对于二分类来说,计算每个实例与最近的其它类的实例距离,并排序
③去除上述距离较远的实例
④去除不影响其它实例预测结果的实例
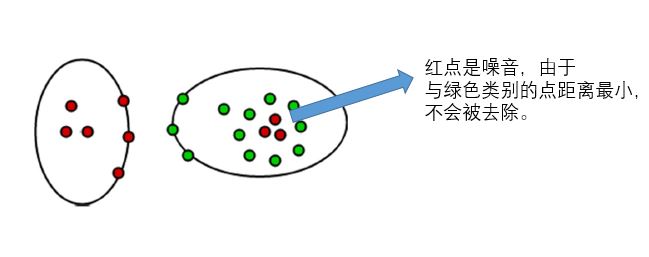
示例

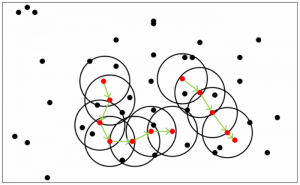
Agglomerative Clustering
目的:解决DROP3算法的问题来构造代理模型(摒弃了KNN算法)
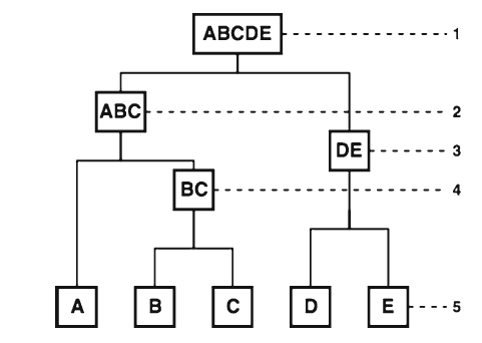
自底向上聚类
首先每个实例自成一类,两个最近的合并为一类,选出每个类的中心实例,加入代理训练集模型。(类的个数等于代理训练集实例大小,用户设置)

你好 , 这位朋友。
我可以知道 Agglomerative Clustering 这个算法是怎么看吗? 我看不懂呢。 可以教导我吗? 谢谢你
不还意思,时间久远,我记不大清楚了