文章目录
特征选择是一种数据预处理过程,优秀的特征能够提升分类器的性能。
在现实世界中,有很多类包含很多特征,比如生物的DNA,在利用不同算法选出较少的特征子集后,如何评价选出来的特征是至关重要的。
从多数特征选择论文中提取以下几点。
①不同特征选择算法在不同数据集上的错误率
②不同特征选择算法在不同数据集上选出解的数目
说明:很显然,以上两点是必须的。
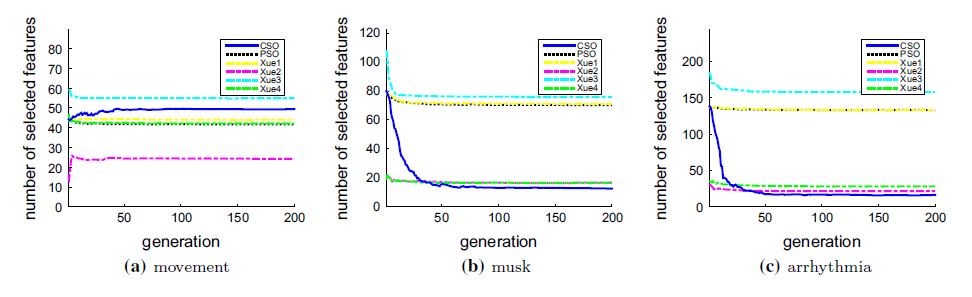
③迭代次数不同情况下出现新解的个数
说明:出现的新解越少,说明算法逐渐收敛,在同一张坐标轴上显示多个算法出现新解的个数可以有效比较算法收敛速度。虽然能比较收敛速度,但是算法不一定差。
下图显示了不同数据集上的迭代次数不同情况下出现新解的个数
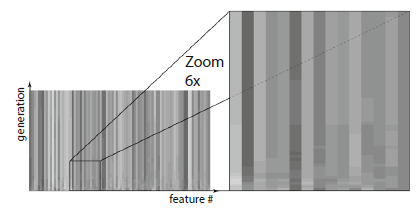
④所有代中每个特征被选中的频率
说明:如果某些解的频率很高,某些解的频率很低,说明此算法比较稳定。
下面这张图就显示了每个特征被选中的频率。如果线条越黑,则说明此特征被选中的频率越大,如果整张图都是灰的,那么这个算法其实还有提升的空间。
下图显示了CSO和PSO算法的情况

⑤不同参数情况下的实验结果
说明:比如PSO算法的c1,c2的权重值,KNN算法不同的K值等。
⑥不同分类器(SVM,KNN)下的实验结果
说明:KNN算法高维(大于5000维)运算会比较耗时,SVM的参数调整较麻烦。