

论文:Ham, Tae Jun, et al. "A^ 3: Accelerating Attention Mechanisms in Neural Networks with Approximation." 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2020.
HPCA,CCF-A体系结构顶会。
随着神经网络计算需求的增长,学术界已经提出了许多用于神经网络的硬件加速器。这种现有的神经网络加速器通常专注于流行的神经网络类型,例如卷积神经网络(CNN)和递归神经网络(RNN)。但是,注意力机制(Attention Mechanism)并没有引起太多关注,注意力机制是一种新兴的神经网络原语,它使神经网络能够从知识库,外部存储器或过去的状态中检索最相关的信息。注意机制已被许多先进的神经网络广泛采用,用于计算机视觉,自然语言处理和机器翻译,并且占总执行时间的很大一部分。
作者设计了一种称为A3的专用硬件加速器,该加速器的目标是利用近似势能的神经网络中的注意力机制。尤其是,A3的工作确定了新兴的神经网络原语的重要性,并通过软件-硬件协同设计使其加速,从而实现了比常规硬件更高数量级的能效提升。此外,A3还为近似注意力机制设计了专用的硬件流水线,同时推出了台积电40nm的测试芯片。实验结果表明,与传统硬件相比,该加速器可实现显着的性能和能效提升。
在章节Ⅱ-A和章节Ⅱ-B部分中,论文表明注意机制是大多数先进的神经网络(如Word2Vec,Glove和FastText)中广泛使用的策略,用于识别和检索与输入有关的数据,即可区分的基于内容的相似性搜索。大多数网络都在自然语言处理,计算机视觉和推荐系统领域。详细分析了注意机制中点积,softmax归一化和权重和的计算过程。此后,本文得出的结论是,在矩阵矢量乘法中执行的大多数计算对最终输出几乎没有影响,因为大多数得分值在softmax归一化之后可以近似并优化为接近零。因此,A3加速器指日可待。
文章介绍了A3的两个不同版本:Base-A3(第III部分)和Approx-A3(第IV和V部分)。 对于前者,每个模块的硬件设计都直接映射到其计算。后者提出了近似机制,因此后者更值得讨论。
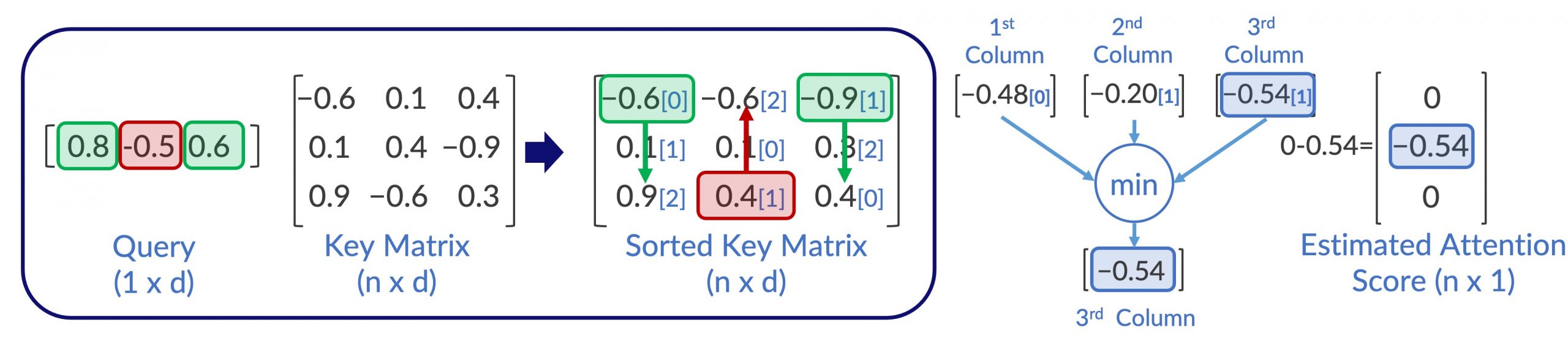
特别是,有关如何设计近似注意力的想法有两个关键步骤。一种是通过有限的计算来识别与注意力机制中的查询相关的候选者。另一个是避免计算可能是不相关的行。有一个关键的直觉:如果我们能以某种方式识别出一些最大和最小的分量相乘结果,就可以用很少的计算来计算估计的注意力得分。
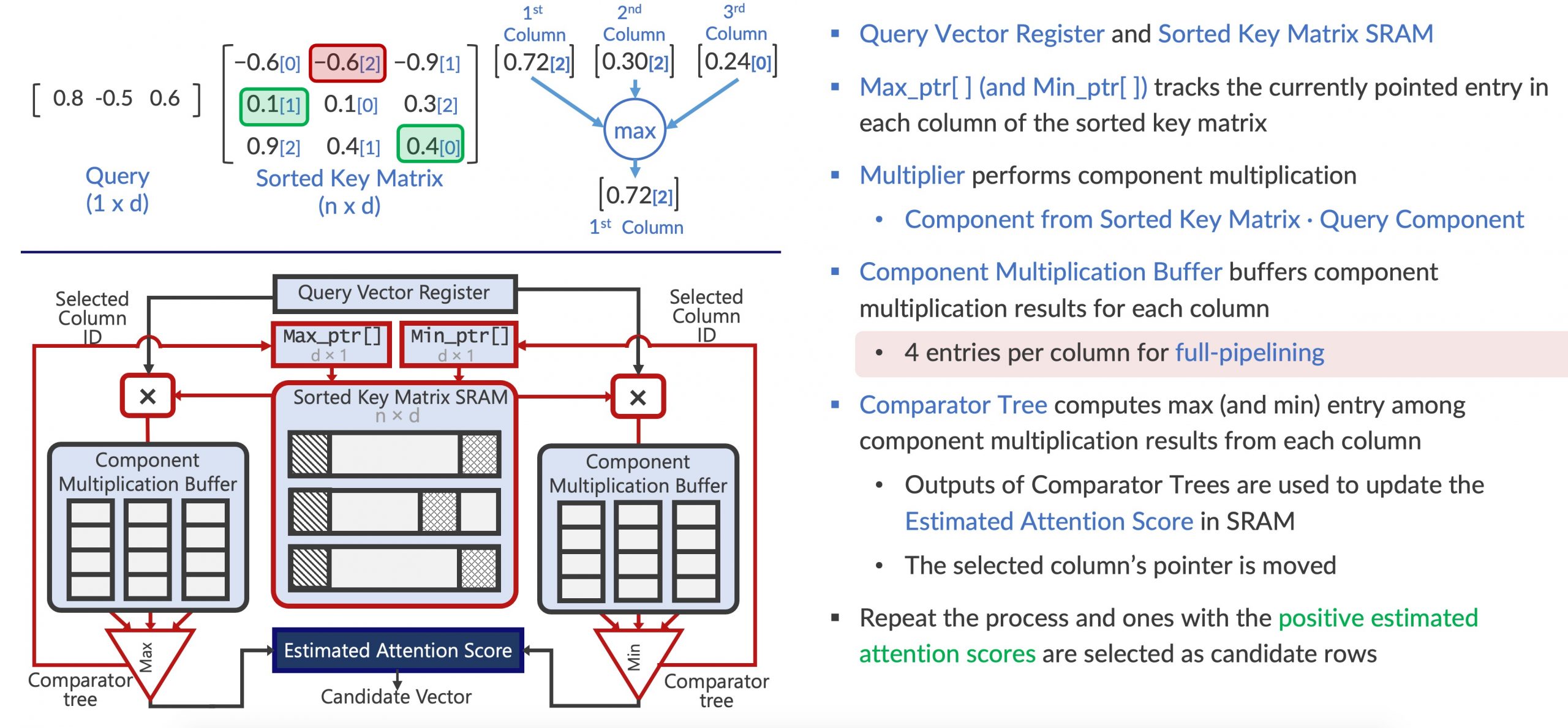
对于Approx-A3,作者设计了一组新的硬件加速器模块,用于候选者选择和评分后逼近。它使用天真的想法,即加法比乘法好。例如,给定大小为n x d的矩阵,Approx-A3首先对存储在SRAM中的矩阵的每一列进行排序。然后,大小为1乘d的两个指针的目的是要获取m次排序列中的max和min个元素,以更新估计的注意力,代替查询向量和排序矩阵的逐元素乘法。因此,该算法仅执行2 x m的乘法,比n x d小得多。简而言之,该算法每次迭代更新两个估计的注意力得分:最大和最小分量相乘结果。最后,经过m次迭代后具有正估计注意力得分的行将成为近似注意力的候选对象。
操作图:
加速器结构:
本文演示了一些评估A3加速器的实验。选择VI分为四个部分:A(工作量),B(准确性评估),C(性能结果)和D(面积,功率,能量和测试芯片)。
从性能结果可以看出,近似可以进一步提高吞吐量(2.6-7.0倍)和等待时间(1.6-8.0倍)。因此,在面积和能源效率方面,可以节省更多的能源(比CPU效率高> 10,000倍)。结果证明,Approx-A3的先前设计非常有效。如果在忽略管芯尺寸的情况下将这种技术应用于移动终端,则这是有用的。此外,应该注意的是,大多数能量都花费在输出计算和候选选择上,这很容易理解,因为逐个元素的乘法被近似值代替。但是,我们都知道近似方案会影响端到端模型的准确性。根据VI-B,结果表明,保守近似方案损失了约1-1.6%的精度指标,而积极近似方案损失了约8-9%的精度指标。此外,选择的前几项的数量表明,激进近似法可能会错过一些注意力得分较高的项目。

Pretty nice post. I just stumbled upon your weblog and wanted to say that I have really enjoyed surfing around your blog posts. Sherye Bronny Hermione
文章写的很好啊,赞(ㆆᴗㆆ),每日打卡~~
又发现一个好站,收藏了~以后会经常光顾的 (。•ˇ‸ˇ•。)