Kaggle简介
Kaggle是由联合创始人、首席执行官安东尼·高德布卢姆(Anthony Goldbloom)2010年在墨尔本创立的,主要为开发商和数据科学家提供举办机器学习竞赛、托管数据库、编写和分享代码的平台。该平台已经吸引了80万名数据科学家的关注,这些用户资源或许正是吸引谷歌的主要因素。
问题简介

包含带标签的训练集与不带标签的测试集
最终提交带列名的csv文件(格式如 gender_submission.csv)
Overview
The data has been split into two groups:
- training set (train.csv)
- test set (test.csv)
The training set should be used to build your machine learning models. For the training set, we provide the outcome (also known as the “ground truth”) for each passenger. Your model will be based on “features” like passengers’ gender and class. You can also use feature engineering to create new features.
The test set should be used to see how well your model performs on unseen data. For the test set, we do not provide the ground truth for each passenger. It is your job to predict these outcomes. For each passenger in the test set, use the model you trained to predict whether or not they survived the sinking of the Titanic.
We also include gender_submission.csv, a set of predictions that assume all and only female passengers survive, as an example of what a submission file should look like.
数据集
包含如下的特征
| Variable | Definition | Key |
|---|---|---|
| survival | Survival | 0 = No, 1 = Yes |
| pclass | Ticket class | 1 = 1st, 2 = 2nd, 3 = 3rd |
| sex | Sex | |
| Age | Age in years | |
| sibsp | # of siblings / spouses aboard the Titanic | |
| parch | # of parents / children aboard the Titanic | |
| ticket | Ticket number | |
| fare | Passenger fare | |
| cabin | Cabin number | |
| embarked | Port of Embarkation | C = Cherbourg, Q = Queenstown, S = Southampton |
Variable Notes
pclass: A proxy for socio-economic status (SES)
1st = Upper
2nd = Middle
3rd = Lower
age: Age is fractional if less than 1. If the age is estimated, is it in the form of xx.5
sibsp: The dataset defines family relations in this way...
Sibling = brother, sister, stepbrother, stepsister
Spouse = husband, wife (mistresses and fiancés were ignored)
parch: The dataset defines family relations in this way...
Parent = mother, father
Child = daughter, son, stepdaughter, stepson
Some children travelled only with a nanny, therefore parch=0 for them.
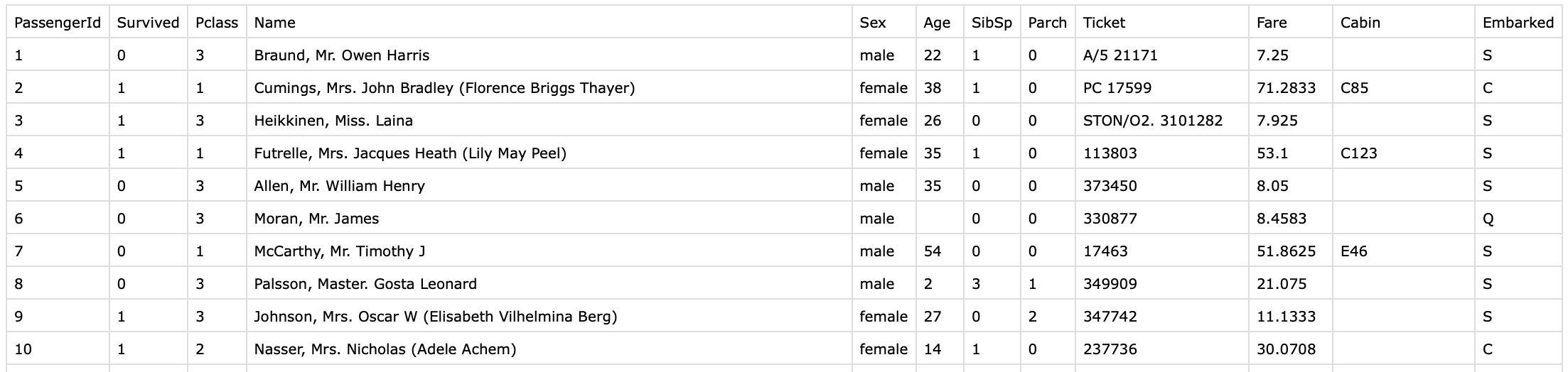
预览
特征工程
我的做法如下:
考虑到我还是擅长MATLAB,下面将从官网上下载的测试集和训练集进行实数画,由于第一次仅仅是入门,我首先将PassengerID这一列特征删除(显然没用),接下来,为了方便,删除了姓名这列(当然为了提高准确率,这一列可以从社会工程学角度进行挖掘分析,在此一切从简),同样地,我删除了Cabin数据严重丢失的这一列,其他Sex这列转换成0和1,Embarked转换成1,2,3。其他无法转换的数据或丢失的数据全部用NaN代替。
最终生成了9个特征的数据集,Survived这一列作为标签Label。
由于9个特征中有较优的特征,也有较劣的特征,我利用改进的PSO特征选择算法选取了较优的特征子集。
分类算法的选择
手写了KNN算法,训练时K=1,预测时选择K=5
生成csv文件并提交
matlab代码:
|
1 2 3 4 5 6 7 8 9 |
load('.mat'); [row,col]=size(labelx); filename='resultnew.csv';%.csv可以更改为.txt等 fid=fopen(filename,'w'); count=0; fprintf(fid,'PassengerID,Survived\n'); for index=1:row fprintf(fid,'%d,%d\n',ansx(index,1),ansx(index,2)); end |
提交结果:
准确率:0.78947
排名:3103/10000

Leaderboard上有多个准确率为1的,估计是对数据集的每个特征进行了分析,并用了高级的分类模型。
入门注意事项
- 注册时要验证用户手机号码,在你的手机号码前加上+860,例如你的手机号为18799999999,那么应该填上 +86018799999999。
- 提交数据时一定要注意数据的格式,不能多个空格和少个空格,Leaderboard上最后有好多准确率为0的,大概都是格式不规范。