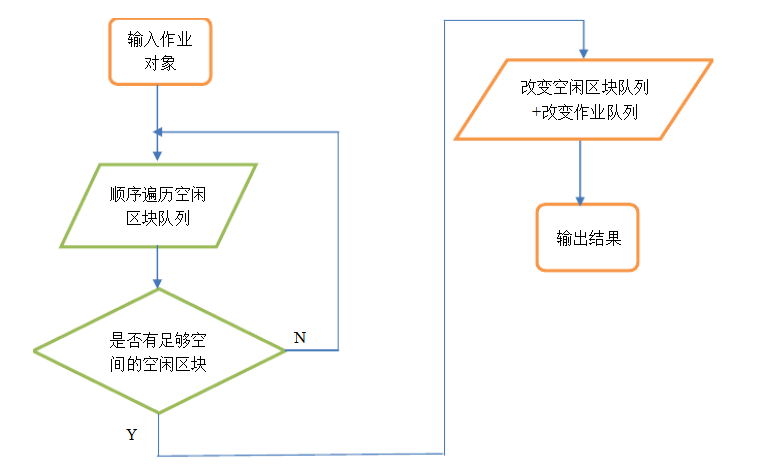
①首次适应算法(First Fit)
FF算法要求空闲分区链以地址递增的次序链接。
-- 在分配内存时,从链首开始顺序查找,直至找到一个大小能满足要求的空闲分区为止;
-- 然后再按照作业的大小,从该分区中划出一块内存空间分配给请求者,余下的空闲分区仍留在空闲链中。
-- 若从链首直至链尾都不能找到一个能满足要求的分区,则此次内存分配失败,返回。
首次适应算法倾向于优先利用内存中低址部分的空闲分区,从而保留了高址部分的大空闲区。这给为以后到达的大作业分配大的内存空间创造了条件。其缺点是低址部分不断被划分,会留下许多难以利用的、很小的空闲分区,而每次查找又都是从低址部分开始,这无疑会增加查找可用空闲分区时的开销。
流程图:
代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 |
#include<stdio.h> #include<stdlib.h> #define TOTAL 1000 typedef struct Lnode{ int id; int size; int start; int end; int flag;//对于内存是是否分配,对于进程是分配编号 struct Lnode *next; }LinkQueue, *QueuePtr; //构造链式队列,用于存储进程和空闲区表 LinkQueue *InitQueue(LinkQueue *Q) { Q = (LinkQueue *)malloc(sizeof(LinkQueue)); Q->next=NULL; return Q; } void showMemory(LinkQueue *Q) { LinkQueue *p; p = (LinkQueue *)malloc(sizeof(LinkQueue)); for(p = Q->next; p!=NULL; p=p->next){ if(p->flag==0){ printf("区号 起始地址 长度 结束地址 \n"); printf("%2d %-5d %-5d %-5d \n",p->id,p->start,p->size,p->end); } } } //n进程编号 分配分区编号 起始位置 长度 终止位置 int InitMemoryFF(LinkQueue *Q) { int i,n; LinkQueue *p,*q[TOTAL]; p = (LinkQueue *)malloc(sizeof(LinkQueue)); for(i = 0; i < TOTAL; i++){ q[i] = (LinkQueue *)malloc(sizeof(LinkQueue)); } p=Q; printf("输入空闲区数量:"); scanf("%d",&n); int start0,size0; for(i = 0; i < n; i++){ printf("输入空闲区起始地址和大小:"); scanf("%d%d",&start0,&size0); q[i]->id = i; q[i]->size = size0; q[i]->start = start0; q[i]->end = start0 + size0; q[i]->flag = 0; q[i]->next = p->next; p->next = q[i]; p = p->next; showMemory(Q); } return i; } LinkQueue *pushProcess(LinkQueue *process,int n,int i,int start0,int size0) { int j=1; LinkQueue *q,*p; q=process; while(q->next){ q=q->next; } p=(LinkQueue *)malloc(sizeof(LinkQueue)); p->id=n; p->flag=i; p->start=start0; p->size=size0; if(p->flag!=0) p->end=start0+size0; else p->end=0;//进程等待 p->next=q->next; q->next=p; return process; } void showProcess(LinkQueue *Process) { LinkQueue *p; int i; p=(LinkQueue *)malloc(sizeof(LinkQueue)); printf("\n进程编号 分配分区编号 起始位置 长度 终止位置\n"); for(i=1,p=Process->next;p!=NULL;p=p->next,i++) { printf("%3d %-5d %-5d %-5d %-5d\n",p->id,p->flag,p->start,p->size,p->end); } } void Allocate(LinkQueue *memory,LinkQueue *process,int num,int size) { LinkQueue *p; p=memory; while(p){ p=p->next; if(!p){ printf("无可用空闲区,进程等待!!!\n"); process = pushProcess(process,num,0,0,size); }else if(p->flag==0&&p->size>=size){ process = pushProcess(process,num,p->id,p->start,size); if(p->flag==0)p->flag=0; p->start=p->start+size; p->size=p->size-size; printf("分配成功!分配分区为:%d\n",p->id); break; } } } LinkQueue *Locate(LinkQueue *Q,int what) { LinkQueue *p; p=Q; while(p&&p->id!=what){ printf("@%d@\n",p->id); p=p->next; } return p; } void Recycle(LinkQueue *memory,LinkQueue *process,int num) { LinkQueue *p,*q,*t,*s; //s,t为辅助结点,t帮助合并后多余删除结点 p=process; q=memory; int i=1,temp; while(p->id!=num&&p) //先找到回收的进程 { printf("@%d@\n",p->id); p=p->next; } while(q&&q->id!=p->flag) //找到回收进程占用的空闲区 { q=q->next; } /////////////////////////////////////////////////////////////////////////////////////// if(q->end==q->next->start) //如果该进程释放后回收的分区可和后一个分区合并 { t=q->next; q->end=t->end; //修改尾地址 q->size+=t->size; //修改分区大小 q->flag=0; //回到未分配状态 q->next=t->next; //删除该结点 free(t); }/////////////////////////////////////////////////////////////////////////////////////// else { printf("BBB..\n"); s=memory; while(s->next!=q) //s指向前一个结点 { s=s->next; } if(s->flag==1) //如果前后都被分配了,则应该新开辟一段空闲分区 { printf("AAA..\n"); //t指向释放进城后得到的新的空闲分区,设置信息,在空闲分区表中新增一个结点 t->id=s->id+1;//新建节点是s的ID加1 t->start=s->end;//起始地址是前一个的尾 t->size=p->size;//大小是该进程的大小 t->end=t->start+t->size; t->flag=0; t->next=s->next; //t插入到空闲分区表中 s->next=t; while(t->next)//后面所有节点的ID加1 { temp=t->id; t=t->next; t->id=temp+1; } } } /////////////////////////////////////////////////////////////////////////////////////// s=memory; while(s->next!=q) //s指向前一个结点 { s=s->next; } if(s->flag==0) //如果该进程释放后回收的分区可和前一个分区合并 { t=q; s->end=t->end; //修改尾地址 s->size+=t->size; //修改分区大小 s->flag=0; //回到未分配状态 s->next=t->next; //删除该结点 free(t); } /////////////////////////////////////////////////////////////////////////////////////// //修改进程表 p=process; while(p&&p->next->id!=num) //先找到回收的进程前一个进程 { p=p->next; } t=p->next; p->next=t->next; free(t); } int develop(LinkQueue *Process, LinkQueue *memory,int m,int count) { LinkQueue *p,*q; q=memory; while(q->next->next) { q=q->next; m++; Process = pushProcess(Process,m,q->id+m,q->end,q->next->start-q->end); } //修改空闲分区表编号 q=memory; while(q->next->next) { q=q->next; p=(LinkQueue *)malloc(sizeof(LinkQueue)); //辅助结点 p->start=q->end; p->end=q->next->start; p->size=p->end-p->start; p->flag=1; //因为是已被分配的空闲分区,所以flag为1 p->id=q->id+1; //因为位置原因,插入到两个空闲分区之间,修改id值 q->next->id=p->id+1; p->next=q->next; q->next=p; q=q->next; } return m; } int main(){ int size; int m=0,count; int num; int flag=1; LinkQueue *memory; LinkQueue *Process; LinkQueue *p,*q; memory=InitQueue(memory); Process=InitQueue(Process); count=InitMemoryFF(memory); m = develop(Process,memory,m,count);//用进程填充空闲分区表中不空闲的部分 printf("\n------空闲链表情况:------\n"); showMemory(memory); printf("\n------进程表情况:------\n"); showProcess(Process); while(flag) { if(flag==1){ m++; //进程编号 printf("\n请输入进程%d所需要的空间大小:",m); scanf("%d",&size); Allocate(memory,Process,m,size); } else if(flag==2) { printf("请输入所释放进程的编号:"); scanf("%d",&num); Recycle(memory,Process,num); } printf("\n------空闲链表情况:------\n"); showMemory(memory); printf("\n------进程表情况:------\n"); showProcess(Process); printf("\n\n1:内存分配,2:回收:"); scanf("%d",&flag); } return 0; } |

下面两个算法类似,写在一起
②最佳适应算法(Best Fit)
所谓“最佳”是指每次为作业分配内存时,总是把能满足要求、又是最小的空闲分区分配给作业,避免“大材小用”。为了加速寻找,该算法要求将所有的空闲分区按其容量以从小到大的顺序形成一空闲分区链。这样,第一次找到的能满足要求的空闲区,必然是最佳的。
孤立地看,最佳适应算法似乎是最佳的,然而在宏观上却不一定。因为每次分配后所切割下来的剩余部分总是最小的,这样,在存储器中会留下许多难以利用的小空闲区。
③最坏适应算法(Worst Fit)
最坏适应分配算法要扫描整个空闲分区表或链表,总是挑选一个最大的空闲区分割给作业使用,其优点是可使剩下的空闲区不至于太小,产生碎片的几率最小,对中、小作业有利,同时最坏适应分配算法查找效率很高。该算法要求将所有的空闲分区按其容量以从大到小的顺序形成一空闲分区链,查找时只要看第一个分区能否满足作业要求。
但是该算法的缺点也是明显的,它会使存储器中缺乏大的空闲分区。
FF与WF代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 |
#include<iostream> #include<algorithm> #include<cstdio> #include<deque> using namespace std; struct Lnode{ int id; int length; int start; int tail; int flag; }; deque<Lnode> freeMemory; deque<Lnode> process; int processNum=0; void showFree() { printf("\n编号 起始位置 长度 终止位置 \n"); for(int i=0;i<freeMemory.size();i++){ cout<<freeMemory[i].id<<"\t"<<freeMemory[i].start <<"\t"<<freeMemory[i].length<<"\t"<<freeMemory[i].tail<<endl; } } void showProcess() { if(process.size()>0) printf("\nPID 起始位置 大小 终止位置 \n"); for(int i=0;i<process.size();i++){ cout<<process[i].id<<"\t"<<process[i].start <<"\t"<<process[i].length<<"\t"<<process[i].tail<<endl; } } int setMemory() { cout<<"---->>输入空闲区的数量:"; int num; cin>>num; struct Lnode temp; int length0; int start0; for(int i=0;i<num;i++){ printf("请输入第%d空闲区的初始地址和大小:\n",i); cin>>start0>>length0; temp.start=start0; temp.length=length0; temp.tail=temp.start+temp.length; temp.id=i; freeMemory.push_back(temp); //showFree(); } return freeMemory.size(); } int addProcess(int num,int flag,int start0,int length0) { struct Lnode temp; temp.id=num; temp.start=start0; temp.length=length0; temp.tail=temp.start+temp.length; temp.flag=flag; process.push_back(temp); processNum++; return process.size(); } void reLabel() { for(int k=0;k<freeMemory.size();k++){ freeMemory[k].id=k; } } int allocate(int num,int length0) { int i; for(i=0;i<freeMemory.size();i++){ if(freeMemory[i].length>length0){ addProcess(num,freeMemory[i].id,freeMemory[i].start,length0); freeMemory[i].start+=length0; freeMemory[i].length-=length0; printf("\n-----分配成功!分配分区为:%d-----\n",freeMemory[i].id); showFree(); break; } else if(freeMemory[i].length==length0){ addProcess(num,freeMemory[i].id,freeMemory[i].start,length0); freeMemory.erase(freeMemory.begin()+i); printf("\n-----分配成功!分配分区为:%d-----\n",freeMemory[i].id); showFree(); break; }else{ continue; } } if(i==freeMemory.size()) cout<<"XXXXXXXX---->>资源不足!!"<<endl; return freeMemory.size(); } int recycle(int num) { int i,temp,Label; for(i=0;i<freeMemory.size();i++){ if(freeMemory[i].id==process[num].flag){ Label=i; break; } } if(i!=freeMemory.size()){ if(process[num].tail==freeMemory[Label].start){ freeMemory[Label].start=process[num].start; freeMemory[Label].length+=process[num].length; } if((Label-1)>=0&&process[num].start==freeMemory[Label-1].tail){ freeMemory[Label].tail=process[num].tail; freeMemory[Label].length+=process[num].length; } }else{ int j; for(j=0;j<freeMemory.size();j++){ if(j-1<freeMemory.size()&&process[num].start>freeMemory[j].tail&&process[num].tail>freeMemory[j+1].start){ process[num].flag=0; process[num].id=j+1; freeMemory.insert(freeMemory.begin()+j+1,process[num]); reLabel(); break; } } if(j==0){ process[num].flag=0; process[num].id=0; freeMemory.push_front(process[num]); reLabel(); } if(j==freeMemory.size()){ process[num].flag=0; process[num].id=j; freeMemory.push_back(process[num]); reLabel(); } } process.erase(process.begin()+num); for(int k=0;k<process.size();k++){ process[k].id=k; } showFree(); showProcess(); return 1; } void dequeSort(char x) { if(x=='s'){ for(int i=0;i<freeMemory.size();++i){ for(int j=0;j<freeMemory.size()-i+1;++j){ if(freeMemory[j+1].length<freeMemory[j].length){ swap(freeMemory[j],freeMemory[j+1]); } } } }else{ for(int i=0;i<freeMemory.size();++i){ for(int j=0;j<freeMemory.size()-i+1;++j){ if(freeMemory[j+1].length>freeMemory[j].length){ swap(freeMemory[j],freeMemory[j+1]); } } } } } int main() { cout<<"------动态分区分配算法FF,BF,WF------\n\n"; setMemory(); int flag=1; while(flag){ cout<<"\n------------------------------------\n"; cout<<"选择操作:1:增加进程,2:空间回收"<<endl; cin>>flag; cout<<"模式选择:FF:1,BF:2,WF:3?"; int way; cin>>way; if(way==2){ dequeSort('r'); }else if(way==3){ dequeSort('r'); } if(flag==1){ cout<<"输入进程需要的大小:"; int size0; cin>>size0; allocate(processNum,size0); cout<<"\n---->>进程表:"<<endl; showProcess(); }else if(flag==2){ cout<<"num:"; int num0; cin>>num0; if(num0>=process.size()) cout<<"XXXXXXXX---->>ERROR"<<endl; recycle(num0); } } } |
网站所有原创代码采用Apache 2.0授权
网站文章采用知识共享许可协议BY-NC-SA4.0授权