什么是多分类问题?
简单地说就是在监督学习下样本实例的标签有多个,而我们很多问题是二分类分体(正确,错误或者是0,1问题)。
很多算法在原理推导上都是假设样本是二分类的,比如SVM、Adaboost等,整个推导过程以至结论都是相对二分类的,根本没有考虑多分类,如果你想直接将SVM直接应用在多分类上是不可能的,除非你在从原理上去考虑多分类的情况,然后得到一个一般的公式,最后在用程序实现这样才可以。通常情况是将多分类转化为二分类问题。
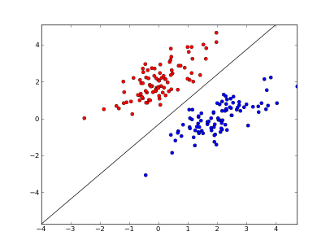
多分类问题转化为二分类问题
很简单,一个简单的思想就是分主次,采取投票机制。转化的方式有两种,因为分类问题最终需要训练产生一个分类器,产生这个分类器靠的是训练样本,前面的二分类问题实际上就是产生了一个分类器,而多分类问题根据训练集产生的可不止是一个分类器,而是多个分类器。
第一种方式就是将训练样本集中的某一类当成一类,其他的所有类当成另外一类。
像上面的5类,我把最中间的一类当成是第一类,并重新赋予类标签为1,而把四周的四类都认为是第二类,并重新赋予类标签维-1,好了现在的问题是不是就是二分类问题了?是的。那二分类好办,用之前的任何一个算法处理即可。好了,这是把最中间的当成一类的情况下建立的一个分类器。同理,我们是不是也可以把四周任何一类自成一类,而把其他的统称为一类呀?当然可以,这样依次类推,我们共建立了几个分类器?像上面5类就建立了5个分类器吧,好了到了这我们该怎么划分测试集的样本属于哪一类了?注意测试集是假设不知道类标签的,那么来了一个测试样本,我把它依次输入到上述建立的5个分类器中,看看最终它属于哪一类的多,那它就属于哪一类了吧。比如假设一个测试样本本来是属于中间的(假设为第5类吧),那么先输入第五类自成一类的情况,这个时候发现它属于第五类,记录一下5,然后再输入左上角(假设为1类)自成一类的情况,那么发现这个样本时不属于1类的,而是属于2,3,4,5这几类合并在一起的一类中,那么它属于2,3,4,5中的谁呢?都有可能吧,那么我都记一下,此时记一下2,3,4,5。好了再到有上角,此时又可以记一下这个样本输入1,3,4,5.依次类推,最后把这5个分类器都走一遍,就记了好多1~5的标签吧,然后去统计他们的数量,比如这里统计1类,发现出现了3次,2,3,4都出现了3次,就5出现了5次,那么我们就有理由认为这个样本属于第五类,那么现在想想是不是就把多类问题解决了呢?
第二种分类方式 ,思想类似,也是转化为二分类问题,不过实现上不同。前面我们是挑一类自成一类,剩下的所有自成一类,而这里,也是从中挑一类自成一类,然剩下的并不是自成一类,而是在挑一类自成一类,也就是说从训练样本中挑其中的两类来产生一个分类器。
像上述的5类,我先把1,2,类的训练样本挑出来,训练一个属于1,2,类的分类器,然后把1,3,挑出来训练一个分类器,再1,4再1,5再2,3,等等(注意2,1与1,2一样的,所以省去了),那这样5类样本需要建立多少个分类器呢?n*(n-1)/2吧,这里就是5*4/2=10个分类器,可以看到比上面的5个分类器多了5个。而且n越大,多的就越多。好了建立完分类器,剩下的问题同样采取投票机制,来一个样本,带到1,2建立的发现属于1,属于1类的累加器加一下,带到1,3建立的发现也属于1,在加一下,等等等等。最后看看5个类的累加器哪个最大就属于哪一类。那么一个问题来了,会不会出现像上面那种情况,有两个或者更多个累加器的值是一样的呢?答案是有的,但是这种情况下,出现一样的概率可比上述情况的概率小多了。
参考文献
https://blog.csdn.net/mysteryhaohao/article/details/51244238