

归一化是将数据映射到[0,1]区间,即构造从原始数据集到[0,1]的双射函数。
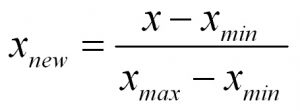
一般做机器学习应用的时候大部分时间是花费在特征处理上,其中很关键的一步就是对特征数据进行归一化,为什么要归一化呢?维基百科给出的解释:
①归一化后加快了梯度下降求最优解的速度
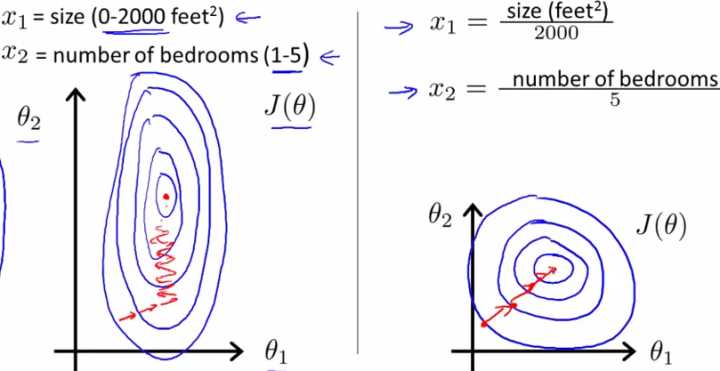
②归一化有可能提高精度
一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、rf。而像adaboost、gbdt、xgboost、svm、lr、KNN、KMeans之类的最优化问题就需要归一化。
更多内容:https://www.zhihu.com/question/20455227


对x做这种归一化处理,在做预测时,预测样本里面如果出现比Max大的值,或者出现比Min小的值,如何处理呢
这个应该是预测的问题吧,在预测里面增加约束?