

DG2有两个主要部分
①生成原始交互关系结构矩阵
包含了每对变量的|∆(1) − ∆(2)|这个阈值
②寻找一个合适的阈值ǫ将原始交互关系结构矩阵Λ转变为处理过的矩阵Θ
Θij 取 1 如果 Λij > ǫ
需要指出的是不像DG,DG2的阈值是在大量函数值和原始交互关系矩阵的基础上获得信息的。这个由ISM函数生成。
③将变量分成不可再分的子成分which is performed by identifying the connected components of the graph with the node adjacency matrix of Θ
作者关注到两大问题
①寻找一个高效的ISM函数生成矩阵,尽量减少函数评估
②寻找一个有效的阈值寻找方法来提高分解的正确率
A 提高DG算法的效率
减少函数重复计算
对于一个n维函数,总交互关系为n(n-1)/2,定理1说明了每个比较需要计算4次,因此,总的评估数量为2n(n-1)次
假定这个函数有3个决策变量f(x1, x2, x3)总评价次数为12次
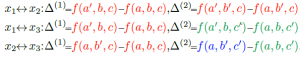
x1↔x2:∆(1)=f(a′, b, c)−f(a, b, c),∆(2)=f(a′, b′, c)−f(a, b′, c)
x1↔x3:∆(1)=f(a′, b, c)−f(a, b, c),∆(2)=f(a′, b, c′)−f(a, b, c′)
x2↔x3:∆(1)=f(a, b′, c)−f(a, b, c),∆(2)=f(a, b′, c′)−f(a, b, c′),
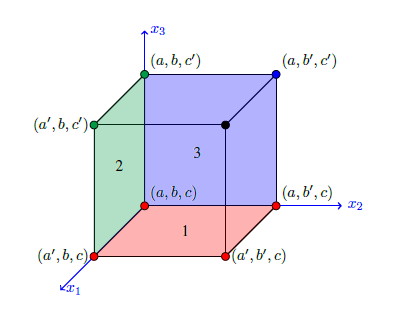
由图可知只需要7个点就能满足
为了计算∆(1)和∆(2)需要四个不同的点来组成一个矩形,为了计算∆(1),一个基点(a,b,c),
和(a’,b,c),为了寻找x1和x2交互关系,因此同样地差分函数∆(1)来评估x2,所以找到了(a’,b’,c’)和(a,b’,c)。其中点(a,b,c)使用了三次。只有一维不同的点(a’, b, c), (a, b’, c),(a, b, c’)
重复了两次,两位不同的点出现了一次。因此,为了计算i维和j维的交互关系作者将到了
n(n+1)/2+1次。详细见ISM方程。
B提高分组准确性。分组准确性取决于ǫ,理论上,这个值可以被设置为0,如果∆(1)和∆(2)的差分为正,说明了两个变量间有交互关系。然而由于存在舍入偏差会导致分组准确率下降。
持续更新,更多内容请阅读原文DG2: A Faster and More Accurate Differential Grouping for Large-Scale Black-Box Optimization
