

之前写了一篇基于NLTK情感预测的文章http://www.omegaxyz.com/2017/12/15/nltk_emotion/?hilite=%27NLTK%27b
情感词典是从微博、新闻、论坛等数据来源的上百万篇情感标注数据当中自动构建的情感极性词典。因为标注包括微博数据,该词典囊括了很多网络用语及非正式简称,对非规范文本也有较高的覆盖率。该情感词典可以用于构建社交媒体情感分析引擎,负面内容发现等应用。
这是一个基于机器学习的已生成的情感词典(txt文档),注意只能预测社交媒体等非规范性文本(文章情感预测精度有误差)
词典下载:https://bosonnlp.com/resources/BosonNLP_sentiment_score.zip
python实现是利用jieba分词预测
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
import time import jieba emotion_dic = {} filename = 'BosonNLP_sentiment_score.txt' # txt文件和当前脚本在同一目录下,所以不用写具体路径 with open(filename, 'rb') as file: while True: try: senList = file.readline().decode('utf-8') # print(senList) senList = senList[:-1] senList = senList.split(' ') emotion_dic[senList[0]] = senList[1] except IndexError: break def get_emotion(score): emotion_archive = ['绝望,十分愤怒,对生活不在抱有希望', '难过,失望,抑郁', '有点小难过或者小愤怒', '轻微的难受或者不屑,想得太多啦,洗洗睡觉吧', '生活也就这样吧', '有点小开心或者小激动', '蛮开心的,生活多美好', '喜笑颜开,每天的太阳都是新的,生活充满了希望'] if score <= -3.9: return emotion_archive[0] elif -3.9 < score <= -2.5: return emotion_archive[1] elif -2.5 < score <= -1: return emotion_archive[2] elif -1 < score <= 0: return emotion_archive[3] elif 0 <score <= 1: return emotion_archive[4] elif 1 < score <= 2.5: return emotion_archive[5] elif 2.5 < score < 3.9: return emotion_archive[6] else: return emotion_archive[7] test = "才拒绝做爱情代罪的羔羊" seg_list = jieba.cut(test, cut_all=True) string = "/ ".join(seg_list) string_list = string.split('/') emotion_index = 0 time.sleep(1) print("-5分为极端消极,5分为非常高兴") for _ in range(len(string_list)): if string_list[_] in emotion_dic: emotion_index += float(emotion_dic[string_list[_]]) print(emotion_index) print(get_emotion(emotion_index)) |
测试文本来自陈奕迅《爱情转移》中“才拒绝做爱情代罪的羔羊”
结果:
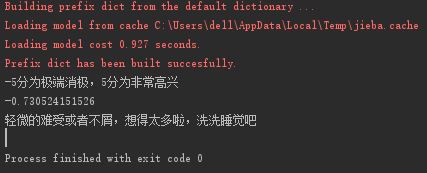
-0.730524151526
轻微的难受或者不屑,想得太多啦,洗洗睡觉吧
网站所有原创代码采用Apache 2.0授权
网站文章采用知识共享许可协议BY-NC-SA4.0授权



