

论文与作者

关于第一作者Bin Wu,他此刻是腾讯AI尝试室的高级研究员,也是王者光彩AI算法计划和开拓的技能认真人。
此前,他还照旧腾讯一个量化买卖营业项目标焦点成员,认真呆板进修算法的计划和开拓。这个团队搞的模子,已经获取了70%的净收益,2017年在A股市场的回报率为5%。
果真的资料表现,Bin Wu于2016年12月插手腾讯至今。此前,他曾在百度供职一年,认真Duer相干的项目。
2011年,Bin Wu本科结业于上海交大,2015年在香港科技大学得到博士学位。
摘要
游戏AI的下一个挑战在于实时策略(RTS)游戏。RTS游戏提供部分可观测的游戏环境,相互作用在操作空间更大。掌握RTS游戏需要强有力的宏观策略和精细的微观层面执行。最近,作者已经取得了很大的进步在微观层面的执行,同时为宏观策略还缺乏完整的解决方案。
本文提出一个新颖的上优于层次宏观策略模型掌握MOBA游戏。训练层次宏观策略模型,代理明确宏观战略决策,进一步引导他们的微观层面执行。此外,每个代理使得独立的战略决策,同时与盟军通过利用一种新颖的交流模仿crossagent通信机制。综合评价一个受欢迎的5 v5多人在线战斗竞技场(MOBA)游戏(王者荣耀)。作者团队与人类玩家团队排名前1%的玩家达到48%的赢率。
王者荣耀与围棋对比
一局王者荣耀均匀时长20分钟,约莫相等于2万帧。
围棋一局凡是不高出361手。
在每一帧画面中,玩家必要在数十个选项中作出抉择,包罗有24个偏向的移动键,以及一些手艺键,有的手艺键尚有偏向。实时颠末大幅简化和离散化,以及把相应时刻增进到200ms,举措空间的数目级仍有101500。
而围棋的举措空间约为10250。
至于状况空间,王者光彩舆图的判别率是130000×130000像素,每个好汉的巨细是1000像素。在每一帧,每个好汉都有差异的状况,如血量、品级、经济等等。即便颠末大幅简化,状况空间仍有1020000。
游戏对战
先看看开局,这是最紧张的阶段之一。下面的四张留意力漫衍图,这些代表着AI学会的差异开局计策。四张图从左到右,别离是:貂蝉(法师)、韩信(刺客)、亚瑟(坦克)和后代(弓手)。

可以看到,AI貂蝉在开局阶段重点存眷中路外塔,AI韩信存眷本方上路野区蓝Buff,AI亚瑟和AI后代存眷本方下路野区红Buff。没有列入的第五个好汉AI宫本武藏,会去捍卫本方上路的外塔。
这就是一个王者光彩的常见开局。
跟着游戏的推进,AI对走位的留意力也会渐渐产生变革。通过下面这个图表可以看到,跟着时刻的推移,AI各个好汉之间的走位也会越来越近。

这种分工联动是这次王者光彩AI最大的晋升之处。
说功效。进级之后的王者光彩AI,为了验证本身的气力,最先找人类练手。五个AI组队开黑,与人类玩家5v5大战250局。末了,AI战队的胜率到达了48%。
这些玩家都是王者段位,属于人类玩家中Top 1%那一部门。
腾讯在论文中暗示,AI战队取得的人头数,比人类战队少15%;而在推塔、团战率和经济获取方面,与人类战队相等。
在开局前10分钟,AI战队比人类战队要多推掉2.5个塔。10分钟之后,因为团战手段较弱,两边的推塔数目渐渐靠近。这个特点被腾讯归纳为:AI在宏观计谋的订定方面,已经靠近乃至优于人类好手。
王者AI背后的算法
AI逼平人类王者,靠的是什么本领?
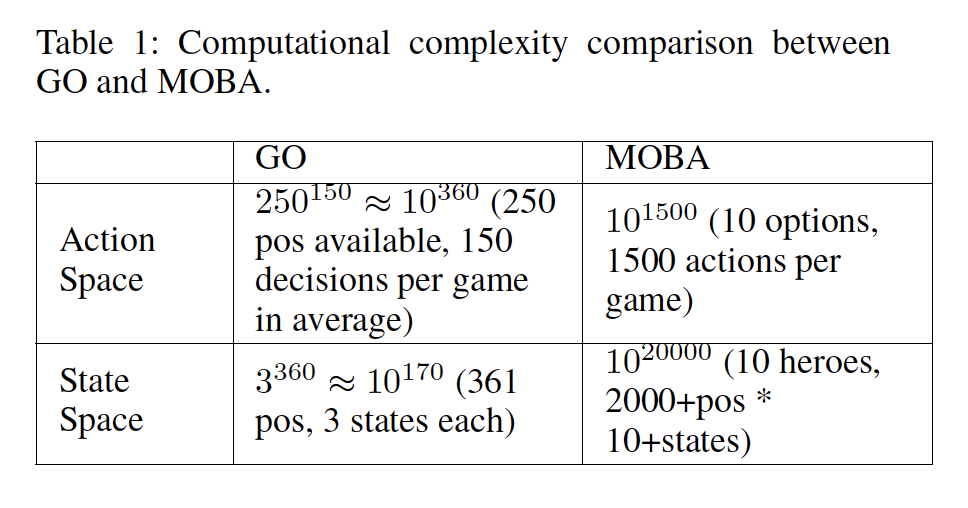
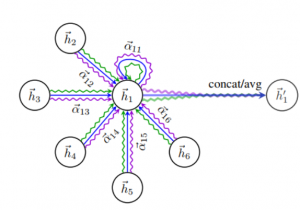
谜底是,一个基于进修的分层宏观计策(Hierarchical Macro Strategy)模子。颠末这个模子的陶冶,节制每个好汉的智能体就既能自力做出决定又不忘与队友雷同,成为顶尖选手。
名字里的“分层”,指的是这个模子分为留意力层(Attention Layer)和时期层(Phase layer),前者用来猜测好汉该去哪儿,后者认真辨认游戏举办到了什么阶段,是前期、对线照旧后期。
我们先看留意力层,也就是AI奈何判定它的好汉该去哪儿。
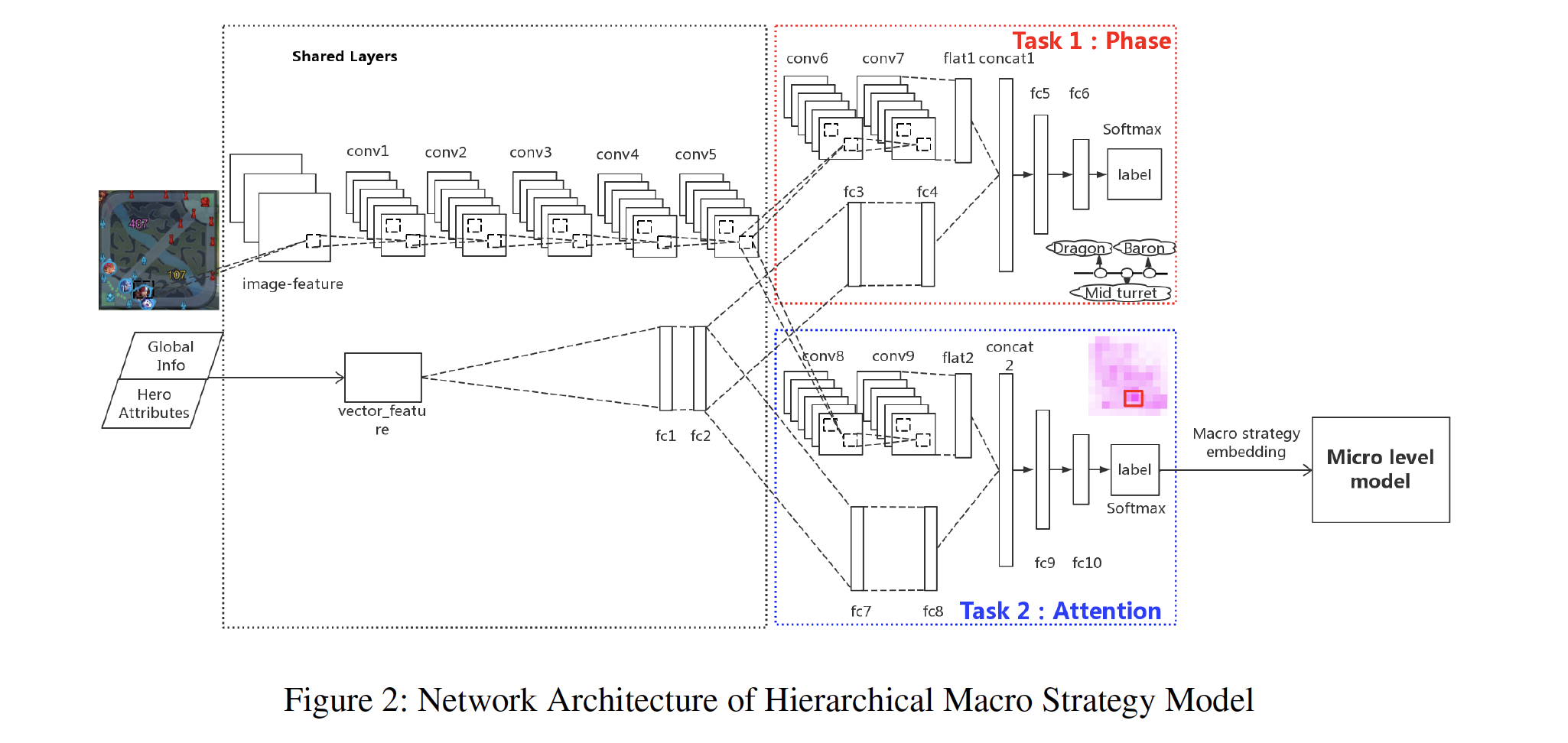
作育这项手段,起重要有吻合的实习数据,而在王者光彩里,想判定好汉“到了这儿”,最吻合的尺度莫过于“在这儿打起来了”。
于是,腾讯在标注实习数据时,把下一次进攻产生的所在,定为好汉此刻该去的所在。
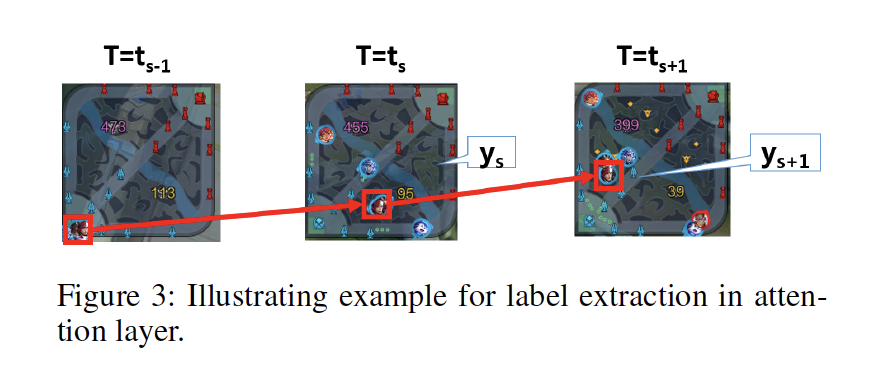
好比说上图就以韩信为例,展示了游戏开局时好汉该往哪走。个中左侧表现的是游戏在初始阶段s-1时的状况,中央和右侧红框标出的ys、ys+1表现的是韩信举办第一、二次进攻的位置,也就是他在s-1、s两个阶段该去的位置。
AI的方针,就是学会在s-1阶段该筹备去y位置,在s阶段该去ys+1位置。
用如许的数据实习留意力层,就能让AI把握好汉移动的奥义。
知道了该去哪还不足,要想上王者,还得会判定大势,调解计策。这就是时期层的事变了。
想知道游戏举办到了前期、对线期照旧后期,只靠时刻虽然不足。亏得游戏里首要资本的状态和阶段密不行分。好比说,假如好汉还在以推外塔打暴君(小龙)为方针,那游戏必然方才开局;假如打到了敌方家里,那虽然是后期了。
以是,教AI判定大势,按照的也是对敌方首要资本的冲击状态,包罗塔、暴君、主宰(大龙)和水晶(base)。
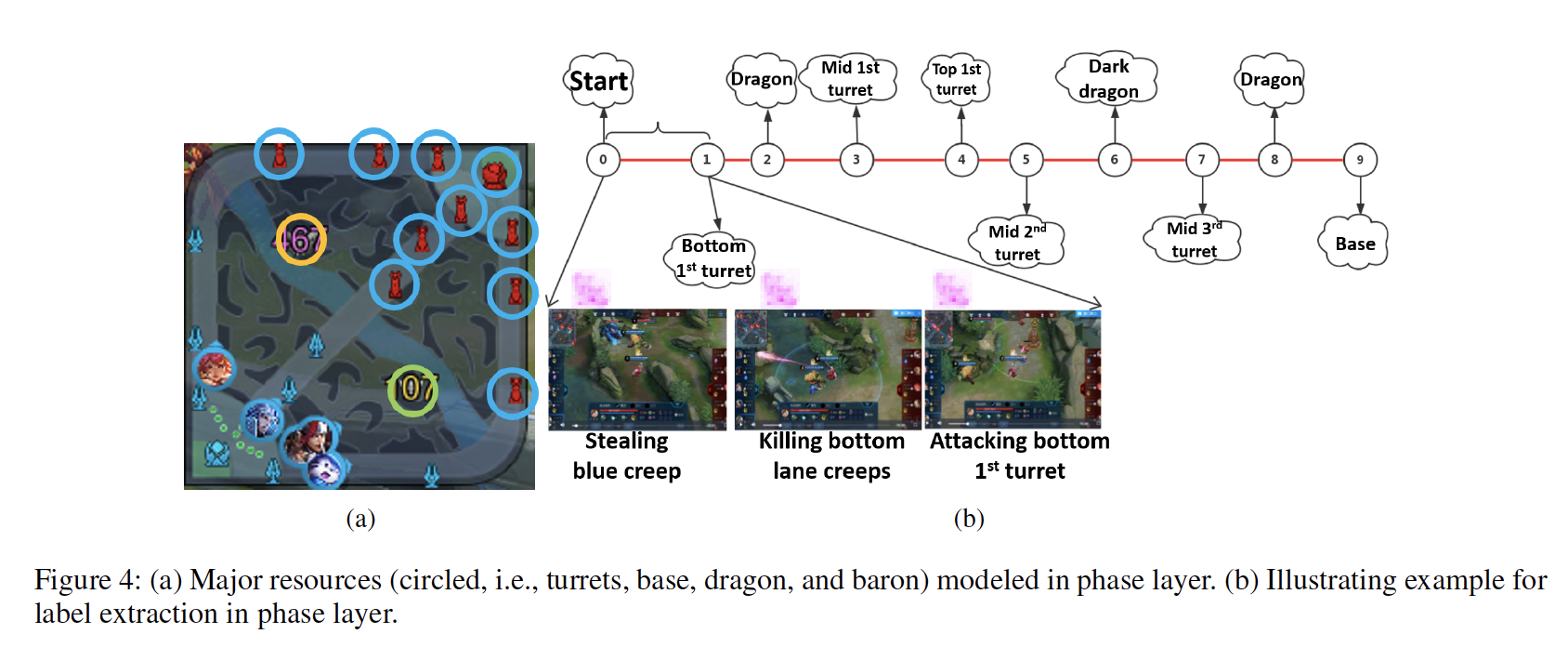
上图左部a表现的就是时期层存眷的敌方首要资本,模子要从中学会的,是按照资本状态来判定此刻该冲击什么首要资本了,并进一步判定要完成哪些小方针。
好比上图右部b表现的偷蓝buff(野怪)、清下路兵线,就都是推一塔这个时期的小方针。
能说明大势、确定方针,还知道该往哪儿走,剩下的就是队友之间的雷同共同题目了。
不外要学雷同,真的没什么人类对战的数据能拿来实习。事实人类队友的雷同布满怨念
于是,腾讯计划了一种全新的跨智能体雷同机制,用队友的留意力标签来实习AI,让它学会猜测队友要往哪走,并据此做出决定。
就如许,一支步队中的5个智能体就可以协作了,也算是一种“雷同”机制吧。腾讯称之为仿照跨智能体雷同(Imitated Crossagents Communication)。

2011年本科毕业,2015年博士毕业。。。
tql…