机器学习中数据集划分是很重要的。
样本数(实例数)较大时采取下面的策略:
如果给定的样本充足,进行模型选择的一种简单方法是随机地将数据集切分成三部分,分为训练集(training set)、验证集(validation set)和测试集(testing set)。训练集用来训练模型,验证集用于模型的选择,而测试集用于最终对学习方法评估。在学习到的不同复杂度的模型中,选择对验证集有最小预测误差的模型。由于验证集有足够多的数据,用它对模型进行选择也是有效的。
Training set与Validation set都是在模型的training过程中使用的:
|
1 2 3 4 5 6 7 8 9 10 11 |
for each epoch for each training data instance propagate error through the network adjust the weights calculate the accuracy over training data for each validation data instance calculate the accuracy over the validation data if the threshold validation accuracy is met exit training else continue training |
testing sets只用来测试模型,来看这个模型究竟有多好,就是评价这个模型的泛化能力(generalization)。 这时候,这个model在testing sets上得到的accuracy就是一个很有代表性(representative)的accuracy,以后再在新的数据集上测试时,也跑不离这个精度的范围。
实际使用时,我们通过训练集学习到参数,再计算交叉验证集上的error,再选择一个在验证集上error最小的模型,最后再在测试集上估计模型的泛化误差。
样本数目较少时采用交叉验证(cross-validation)
k-fold cross validation的目的不是为了选择模型,而是先是有了一个模型,对这个模型进行精度评定。
方法:
交叉验证法”(cross validation)先将数据集 DD划分为k个大小相近的互斥子集,即D=D1∪D2∪…∪Dk,Di∩Dj=∅D=D1∪D2∪…∪Dk,Di∩Dj=∅. 每个子集 DiDi都尽可能保持数据分布的一致性,即从DD中通过分层采样得到。然后,每次用k−1k−1个子集的并集作为训练集,余下的那个子集则作为测试集;这样就可以得到kk组训练/测试集,从而可进行kk组训练和测试,最终返回的是这kk个测试结果的均值。显然,交叉验证评估结果的稳定性和保真性在很大程度上取决于kk的取值,为了强调这一点,通常把交叉验证法称为“kk折交叉验证”(k-fold cross validation)。kk最常用的取值是10,此时称为10折交叉验证。
将数据集DD划分为kk个子集存在多种划分方式。为减小因样本划分不同而引入的差别,kk折交叉验证通常要随机使用不同的划分重复pp次,最终的评估结果是这pp次kk折交叉验证结果的均值,例如常见的有“10次10折交叉验证”(10次10折交叉验证,进行了100次训练/测试)。
假定数据集DD中包含mm个样本,若令k=mk=m,则得到了交叉验证法的一个特例:留一法(Leave-One-Out,简称LOO)。显然,留一法不受随机样本划分方式的影响,因为mm个样本只有唯一的方式划分为mm个子集——每个子集包含一个样本;留一法使用的训练集与初始数据集相比只少了一个样本,这就使得在绝大多数情况下,留一法中被实际评估的模型与期望评估的用DD训练出的模型很相似。因此,留一法的评估结果往往被认为比较准确。然而,留一法也有其缺陷:在数据集比较大时,训练mm个模型的计算开销可能是非常巨大的(例如数据集包含100万个样本,则需训练100万个模型),而这还是在未考虑算法调参的情况下,另外,留一法的评估结果也未必比其他评估方法准确;“没有免费的午餐”定理对实验评估同样适用。
——周志华《机器学习》
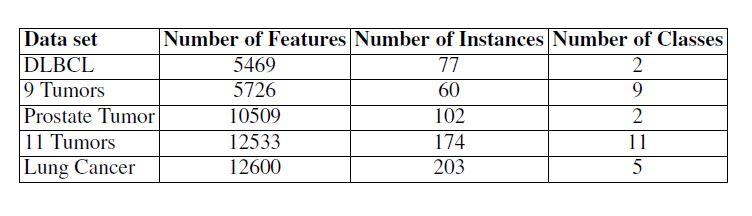
看这下面这个表中的数据集,实例最多只有200,因此采用交叉验证。
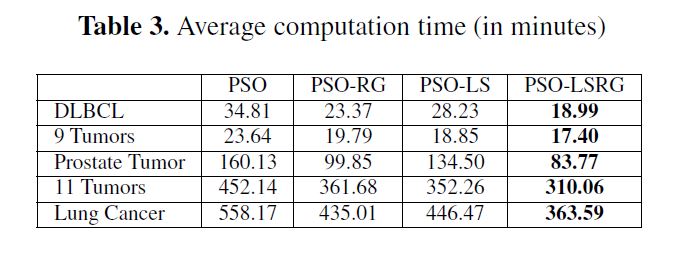
作者采用的是基于变体KNN的LOOCV(留一法)交叉验证,可以看到耗时很长。