假设在C:\Record下面有若干个.txt文件,均为纯英文文档。以这些文档为内容,实现一个本地搜索引擎,当用户给出某个输入时,列出相关的搜索结果。可以自行决定改搜索引擎的功能强弱,并给出有关的说明文档。(可考虑NLTK)
说明文档:
主要步骤
1:
如何设计一个搜索引擎,最简单的是直接在文档列表中利用最简单的模式匹配算法如KMP算法进行查找,当然这一项在Python中只要1行就能完事。
2:
接下来我想到可以利用正则表达式进行模式匹配,这样能够增强匹配的准确性。于是我写了一个10行左右的模式匹配的函数(fuzzy_finder_by_interval(key, name_list))能够根据用户输入和字典序进行模糊搜索。
3:
本以为这样就万事大吉了,但是我在测试时发现利用正则表达式搜索
learning python和python learning的结果不一样,于是我就利用nltk.tokenize模块进行对输入词的划分(这在搜索文件名比较长时才能体现出优势)这样不管哪个单词在前都能够得到一致的结果。
4:
考虑到我们平时搜索时有时候懒得打空格符,即直接输入learningpython,如此的话即使用NLTK的简单功能和正则表达式也得不到正确的结果。于是我想到了对输入的词进行划分。这时就要用到了外部字典文件,我把常用的单词和计算机专业词汇导入到txt文件中(不太清楚NTLK是否有类似的功能,寒假再研究一下,这里先把我想要做的实现一下)如图,这样,对每个连续的字符串能够进行自然语言的划分。这里用到的是正向最大匹配算法。

5:
这样一个正确的搜索引擎就完工了。最后为了使查找到的结果更加精确我从博客http://blog.csdn.net/sky_money/article/details/7957996学习到拼写检查器的基本原理,并利用朴素贝叶斯算法对字典txt文件中的常用单词进行训练,对拼写错误进行更正(当然如果用户不希望开启自动更正也可以)比如我输入了learning pkthon这种输入错误的字符串能够自动改为learning python这样搜索更加精确。
其它:
利用os.walk()进行文件遍历操作。另外自己写了一个函数用来生成大量无关txt文件。
代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 |
import os import re import collections from nltk.tokenize import TreebankWordTokenizer all_file = [] word_list = [] get_list = [] outcome = [] alphabet = 'abcdefghijklmnopqrstuvwxyz' file_path = '**********' dictionary = '**********' NWORDS = [] def visit_dir(path): '''文件读取''' if not os.path.isdir(path): print("ERROR") return list_dirs = os.walk(path) for root, dirs, files in list_dirs: for f in files: all_file.append(os.path.join(root, f)[len(path)+1:]) def load_dic(): global NWORDS '''字典读取''' f = open(dictionary, 'r') NWORDS = train(words(f.read())) for line in f: nlen = len(line)-1 word_list.append(line[:nlen]) f.close() def divide_str(note, wordlist): '''连续字符串划分如iloveyou划分为 i love you''' i = 10 head = 0 flag = 0 while head <= len(note) - 1: if head >= (len(note)-i): i = len(note)-head for p in range(i): rear = head + i - p flag = 0 for each in wordlist: if note[head:rear] == each: get_list.append(each) head = head + len(each) flag = 1 break if flag == 1: break if flag == 0: head = head + 1 def fuzzy_finder_by_interval(key, name_list): '''根据字典序和输入排序的模糊搜索''' key = key.strip() findings = [] pattern = '.*?'.join(key) regex = re.compile(pattern) for item in name_list: match = regex.search(item) if match: findings.append((len(match.group()), match.start(), item)) return [x for _, _, x in sorted(findings)] def words(text): return re.findall('[a-z]+', text.lower()) def train(features): model = collections.defaultdict(lambda: 1) for f in features: model[f] += 1 return model def edits1(word): splits = [(word[:i], word[i:]) for i in range(len(word) + 1)] deletes = [a + b[1:] for a, b in splits if b] transposes = [a + b[1] + b[0] + b[2:] for a, b in splits if len(b) > 1] replaces = [a + c + b[1:] for a, b in splits for c in alphabet if b] inserts = [a + c + b for a, b in splits for c in alphabet] return set(deletes + transposes + replaces + inserts) def known_edits2(word): return set(e2 for e1 in edits1(word) for e2 in edits1(e1) if e2 in NWORDS) def known(words): return set(w for w in words if w in NWORDS) def correct(word): candidates = known([word]) or known(edits1(word)) or known_edits2(word) or [word] return max(candidates, key=NWORDS.get) load_dic() visit_dir(file_path) tokenizer = TreebankWordTokenizer() my_input = input("请输入文件名称:") if ' ' not in my_input: divide_str(my_input, word_list) my_input = get_list else: my_input = tokenizer.tokenize(my_input) print(my_input) for i in range(len(my_input)): my_input[i] = correct(my_input[i]) print(my_input) for i in range(len(my_input)): temp = fuzzy_finder_by_interval(my_input[i], all_file) for j in range(len(temp)): if temp[j] not in outcome: outcome.append(temp[j]) print(outcome) |
运行测试及截图:
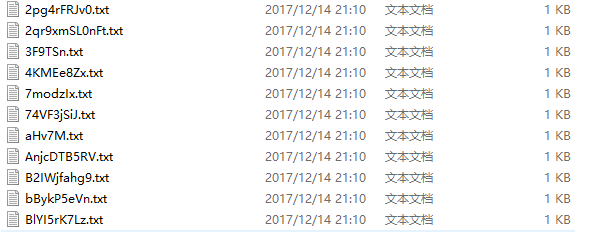
生成的一些包含learning python的测试的txt文件

①查找pythonlearning(无空格查找)
②查找learning python(正常查找)
③查找 learning ptdthons(输入错误)
以上三种情况都能讲上述五个文件搜索出来!